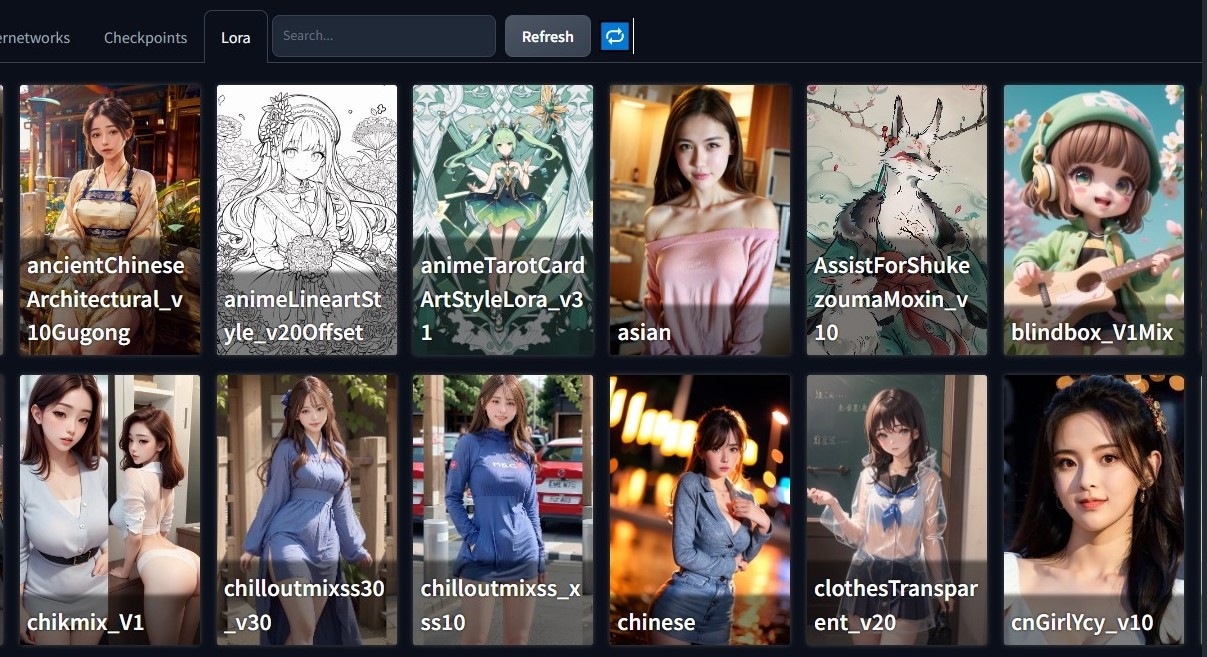
我行 4090 desktop 9秒gen1張128 step 圖
我仲用自己女神 checkpoint 、自己女神Lora 同textual inversion embeddings




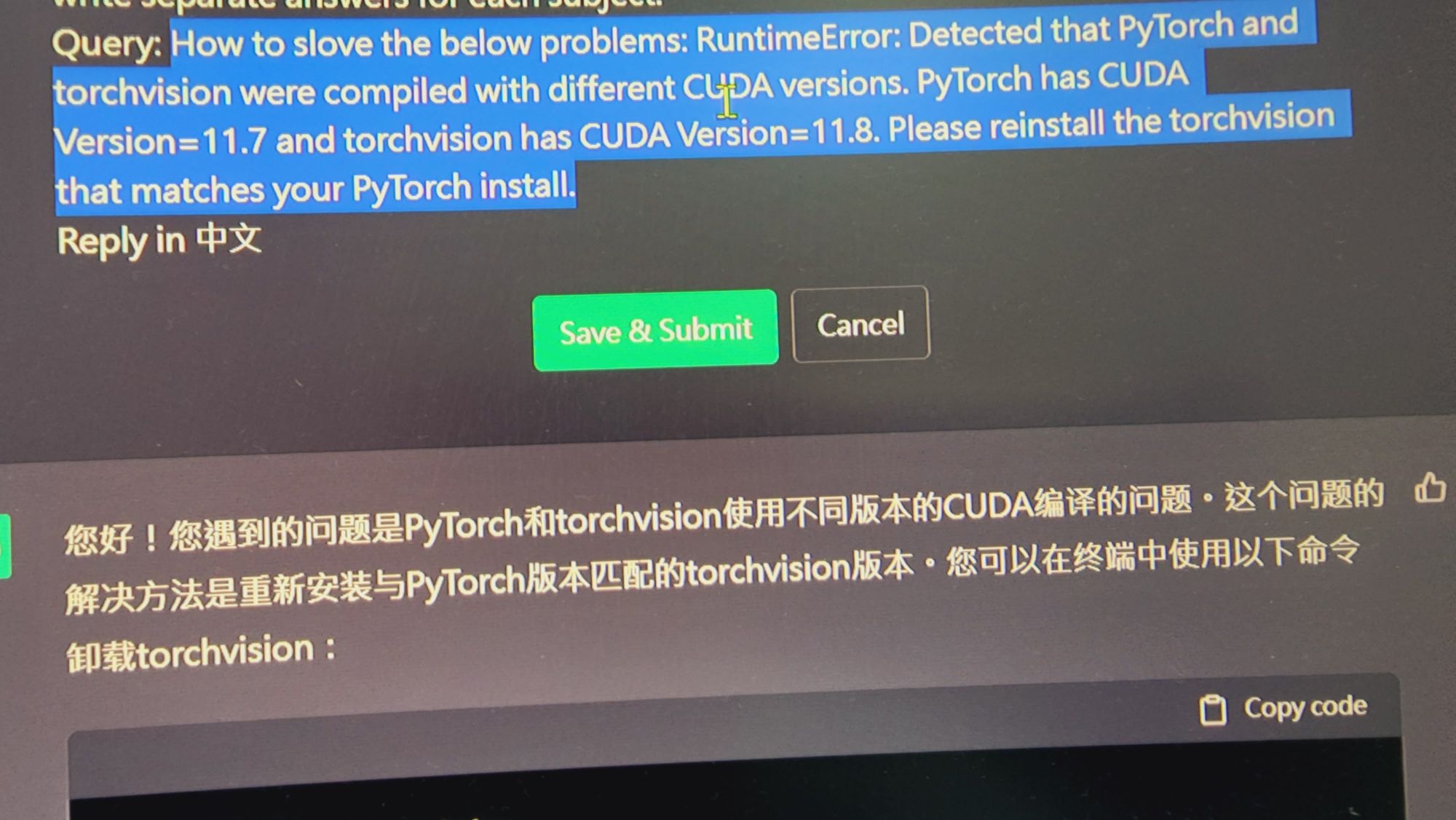
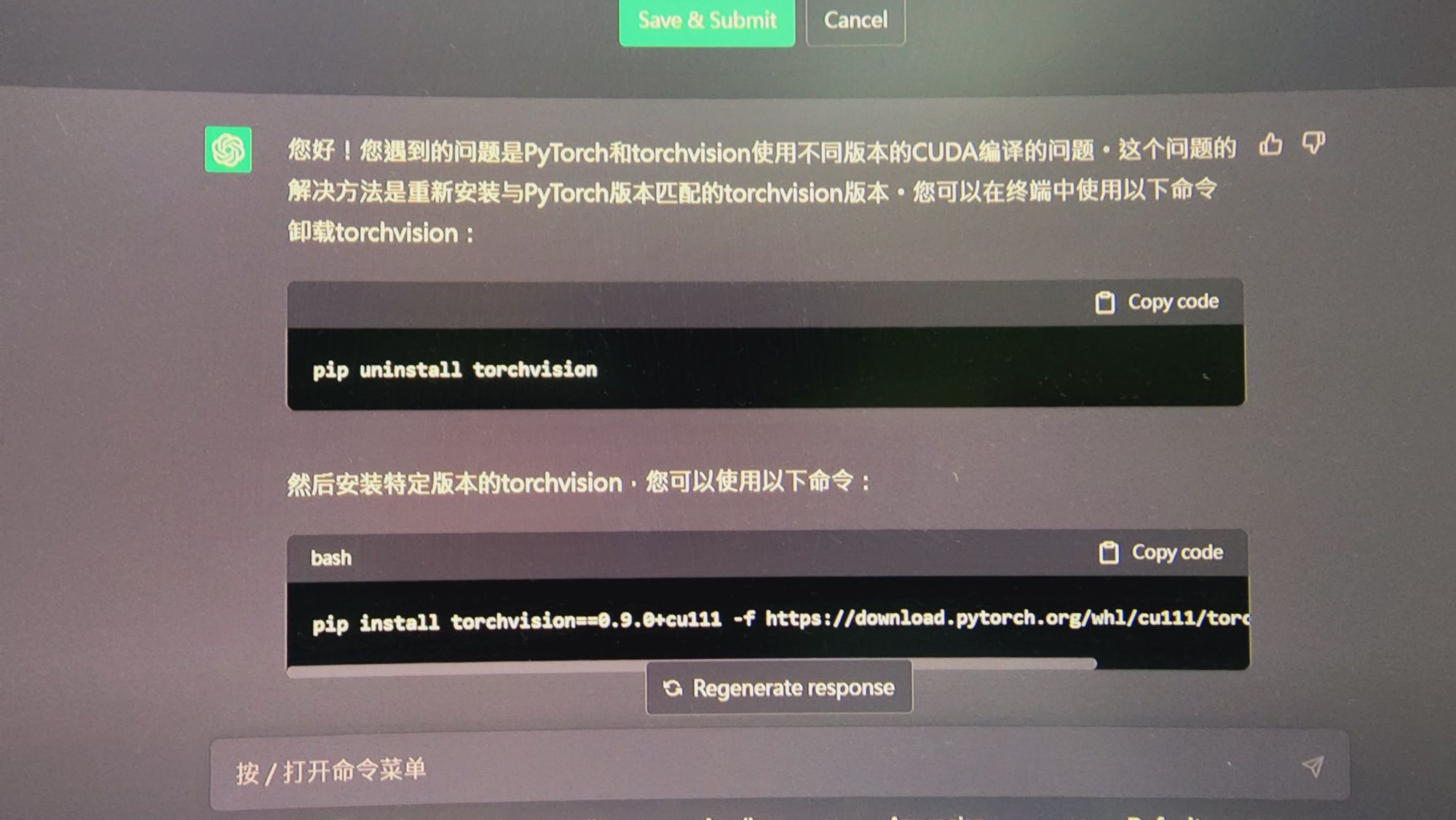
parameters
ultra high res,detailed shadow, best quality, depth of field,1girl,(16-year-old girl),portrait,front view half body,
,(angry:1.2),(street),short hair, <lora:studioGhibliStyle_offset:1.2>,assault rifle:1.2,military uniform, military hat, close up shot,screaming,
Negative prompt: paintings, sketches, (worst quality,low quality,normal quality:1.9), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, glans,nipples, watermark, signature, text,(bad finger),bad anatomy, bad hands,(six_fingers),(nail_art),nail polish,(multiple views:1.5),(hat)
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 7, Seed: 2752815644, Size: 512x768, Model hash: 7f96a1a9ca, Model: anythingV5Anything_anythingV5PrtRE, Denoising strength: 0.5, Hires upscale: 2, Hires steps: 20, Hires upscaler: R-ESRGAN 4x+ Anime6B



Checkpoints,Lora,Textual Inversion,Hypernetworks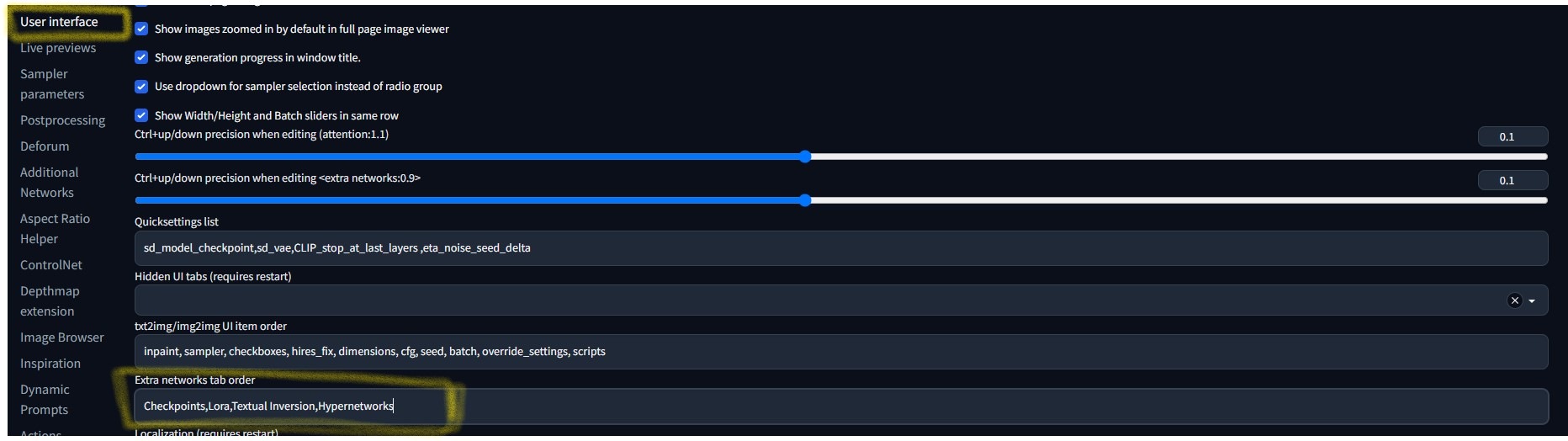
 搵唔到個感嘆號
搵唔到個感嘆號















