
[耳機撚]召集大耳牛、枱式耳機系統用家(18)
我係打手
1001 回覆
4 Like
1 Dislike
第 1 頁第 2 頁第 3 頁第 4 頁第 5 頁第 6 頁第 7 頁第 8 頁第 9 頁第 10 頁第 11 頁第 12 頁第 13 頁第 14 頁第 15 頁第 16 頁第 17 頁第 18 頁第 19 頁第 20 頁第 21 頁第 22 頁第 23 頁第 24 頁第 25 頁第 26 頁第 27 頁第 28 頁第 29 頁第 30 頁第 31 頁第 32 頁第 33 頁第 34 頁第 35 頁第 36 頁第 37 頁第 38 頁第 39 頁第 40 頁第 41 頁
睇software先,有冇SRC之類
仲有啲玄學嘢...
有人話用同一個setup用唔同USB cable都會唔同聲添
仲有啲玄學嘢...
有人話用同一個setup用唔同USB cable都會唔同聲添

邊啲嘢有SRC?
假設用唔同DEVICE出都係一樣SAMPLE RATE, 係咪即係一鳩樣?
另外一個問題,RIP CD用唔同DRIVE RIP係咪真係有分別?唔係全部都係DIGITAL FILE嚟㗎咩?咩24K CD 玻璃CD 同普通CD真係有分別?
另外,EAC嘅作用係可以某程度上修復SCRATCHES?
假設用唔同DEVICE出都係一樣SAMPLE RATE, 係咪即係一鳩樣?
另外一個問題,RIP CD用唔同DRIVE RIP係咪真係有分別?唔係全部都係DIGITAL FILE嚟㗎咩?咩24K CD 玻璃CD 同普通CD真係有分別?
另外,EAC嘅作用係可以某程度上修復SCRATCHES?
純粹想學嘢
仲有個問題 320kbps mp3究竟CUT咗啲咩資料?上網睇佢都係行16/44.1?
大概有個low pass filter 係15kHz 左右。
同埋low end 都有high pass filter ,但唔記得幾多Hz. 好似係20Hz..
係headphones 聽無咁覺,但如果係喇叭聽, mp3/aac 會好似成個stereo image 窄晒。 同lossless a/b 比嘅話好似mono vs stereo 咁。
同埋low end 都有high pass filter ,但唔記得幾多Hz. 好似係20Hz..
係headphones 聽無咁覺,但如果係喇叭聽, mp3/aac 會好似成個stereo image 窄晒。 同lossless a/b 比嘅話好似mono vs stereo 咁。

睇software先
你睇琴日有巴打都講Foobar同JRiver都會唔同聲
RIP CD用唔同drive,唔同轉速 RIP都有唔同
其中一個原因係optical read唔係一個完美方法
CD碟轉個時光頭read data係有機會因為CD反射得唔夠好而係同一個位置讀到唔同value,所以先會有用唔同物料去做CD去改善呢類問題
CD drive震少d,CD轉速穩定d呢d都對讀碟有影響
同埋減慢轉速都會read得準d
所以認真rip 碟個班成日話用6個鐘rip一次、一共rip幾次再cross check、CD drive都都特別處理等等
而實際又聽得到有影響個下先煩
早排有朋友tune緊個rip碟setup個時比ABC對比同一張碟用唔同drive+唔同setting rip,三個結果都有小小唔同
不過你話係唔係差得好遠?我又唔覺大到聽得入耳vs聽唔入耳
所以你願意負出幾多心機rip碟睇你有幾多愛同執著
我就懶,反正點read都未必同個CD master一樣,買檔算
rip碟我都係一買返黎即刻rip,唔比其他機播先
遲d如果有心機先玩rip 碟
未必得,始終就算checksum 一樣唔代表內容一樣
e.g. 15 = 14+1 = 7+8
你睇琴日有巴打都講Foobar同JRiver都會唔同聲
RIP CD用唔同drive,唔同轉速 RIP都有唔同
其中一個原因係optical read唔係一個完美方法
CD碟轉個時光頭read data係有機會因為CD反射得唔夠好而係同一個位置讀到唔同value,所以先會有用唔同物料去做CD去改善呢類問題
CD drive震少d,CD轉速穩定d呢d都對讀碟有影響
同埋減慢轉速都會read得準d
所以認真rip 碟個班成日話用6個鐘rip一次、一共rip幾次再cross check、CD drive都都特別處理等等
而實際又聽得到有影響個下先煩
早排有朋友tune緊個rip碟setup個時比ABC對比同一張碟用唔同drive+唔同setting rip,三個結果都有小小唔同
不過你話係唔係差得好遠?我又唔覺大到聽得入耳vs聽唔入耳
所以你願意負出幾多心機rip碟睇你有幾多愛同執著
我就懶,反正點read都未必同個CD master一樣,買檔算
rip碟我都係一買返黎即刻rip,唔比其他機播先
遲d如果有心機先玩rip 碟
EAC嘅作用係可以某程度上修復SCRATCHES
未必得,始終就算checksum 一樣唔代表內容一樣
e.g. 15 = 14+1 = 7+8
例如我用cd裝隻game,照你咁講個光頭讀隻game嘅data咪會有差錯,點解唔會corrupt?

sorry 又有嘢問
1. massdrop粒pre order制係咪就係等於買嘢?
2. 佢本身係得美國插頭 轉插要自己買 呢個係正常情況?
3. 直送香港嘅話有冇伏?(有冇咩要注意?)22蚊美金其實都ok 但見之前個個都集運
thxxx
1. massdrop粒pre order制係咪就係等於買嘢?
2. 佢本身係得美國插頭 轉插要自己買 呢個係正常情況?
3. 直送香港嘅話有冇伏?(有冇咩要注意?)22蚊美金其實都ok 但見之前個個都集運
thxxx
順便簡介下mp3個原理
mp3 係lossy,其實所有目前常用 lossy codec, e.g. AAC原理應該差唔多
首先,聽覺對音樂處理主要受兩樣Auditory masking影響: Temporal masking, Simultaneous masking (Amplitude masking)
Simultaneous masking好易理解。係地鐵車廂行緊時候講野,你要講大聲d人地先可以聽得到。兩個音一齊出,如果其中一個音「太細聲」,咁你就會「聽唔到」。
咩係「太細聲」呢?
首先係睇人耳個hearing threshold,呢張圖之前有巴打share 過

聲壓唔過hearing threshold係人耳「聽唔到」
不過因為有Simultaneous masking,當有聲存在,個hearing threshold會唔同咗

例如同時係200Hz付近同時有兩個音,2xxHz個音大聲而1xxHz個音細聲。
2xxHz個音因為大聲d,所以屬於佢個mask會遮咗付近頻率,令到付近頻率的hearing threshold高咗,所以1xx Hz個音因為唔過個新hearing threshold所以就會「聽唔到」。
呢個效果就係Simultaneous masking
其實所有聲都會互相mask,你聽到乜主要睇邊d音夠大聲,高過其他音masking level
我起點知一個音出個時會點mask付近frequency?呢個就用psychoacoustic model去模擬。點做出黎我就唔識
Temporal masking就冇咁好理解。兩個音接近同時出現個時,大聲d個音會遮咗細聲個音。唔識舉例
有咗上面認知就可以了解mp3 個原理。mp3先將同一時間所有audio frequency應用psychoacoustic model 分析,從而知道邊d frequency聽得到。「聽唔到」個d就唔encode。另外,個frequency愈大聲就用愈多bit去encode
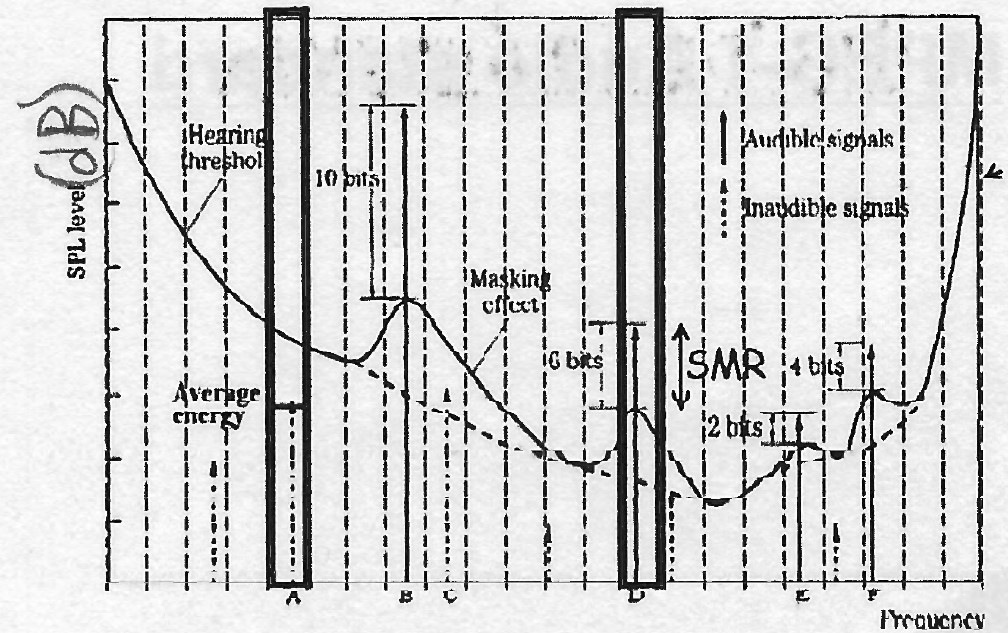
所以mp3係會將「聽唔到」嘅野掉走,而且咁同聲壓用唔同data length記住,從而達到壓縮
sampling rate會照用source sample rate, 16 bit係最大bit depth
聽起上黎mp3分析力唔太好,動態唔夠,高低頻失真幾明顯
mp3 係lossy,其實所有目前常用 lossy codec, e.g. AAC原理應該差唔多
首先,聽覺對音樂處理主要受兩樣Auditory masking影響: Temporal masking, Simultaneous masking (Amplitude masking)
Simultaneous masking好易理解。係地鐵車廂行緊時候講野,你要講大聲d人地先可以聽得到。兩個音一齊出,如果其中一個音「太細聲」,咁你就會「聽唔到」。
咩係「太細聲」呢?
首先係睇人耳個hearing threshold,呢張圖之前有巴打share 過
聲壓唔過hearing threshold係人耳「聽唔到」
不過因為有Simultaneous masking,當有聲存在,個hearing threshold會唔同咗
例如同時係200Hz付近同時有兩個音,2xxHz個音大聲而1xxHz個音細聲。
2xxHz個音因為大聲d,所以屬於佢個mask會遮咗付近頻率,令到付近頻率的hearing threshold高咗,所以1xx Hz個音因為唔過個新hearing threshold所以就會「聽唔到」。
呢個效果就係Simultaneous masking
其實所有聲都會互相mask,你聽到乜主要睇邊d音夠大聲,高過其他音masking level
我起點知一個音出個時會點mask付近frequency?呢個就用psychoacoustic model去模擬。點做出黎我就唔識
Temporal masking就冇咁好理解。兩個音接近同時出現個時,大聲d個音會遮咗細聲個音。唔識舉例
有咗上面認知就可以了解mp3 個原理。mp3先將同一時間所有audio frequency應用psychoacoustic model 分析,從而知道邊d frequency聽得到。「聽唔到」個d就唔encode。另外,個frequency愈大聲就用愈多bit去encode
所以mp3係會將「聽唔到」嘅野掉走,而且咁同聲壓用唔同data length記住,從而達到壓縮
sampling rate會照用source sample rate, 16 bit係最大bit depth
聽起上黎mp3分析力唔太好,動態唔夠,高低頻失真幾明顯
係會有機會讀錯。不過唔同file format個check sum同recovery機制唔同,所以容錯程度都唔同
1. 係,佢要你比付款資料,出貨先扣數
2. 正常。建議去高明買個美制轉英制反相轉插,大約$150
3. 直送香港其實ok,我都係伏過一次。不過怕就用buyandship
2. 正常。建議去高明買個美制轉英制反相轉插,大約$150
3. 直送香港其實ok,我都係伏過一次。不過怕就用buyandship
唔係好熟,等-$0.2巴打出手
其實好睇錄音同器材
bit depth黎講,如果你錄嘅野dynamic range係 within 96 dB,咁16bit夠用,24bit亦唔會有分別
反而sampling rate分別就明顯d,因為data多咗,細節會多d
其實好睇錄音同器材
bit depth黎講,如果你錄嘅野dynamic range係 within 96 dB,咁16bit夠用,24bit亦唔會有分別
反而sampling rate分別就明顯d,因為data多咗,細節會多d
*data point多咗
唔該晒巴打
可唔可以講下點伏法
可唔可以講下點伏法
寄失
不過成功退款
不過成功退款


其實買二手定買全新好?我諗住長用
依家果報a845用咗成10年,係我中學做KFC買返嚟
聽兩個鐘就收皮

仲諗住直送香港唔駛煩  咁都係buyandship集運算
咁都係buyandship集運算
咁都係buyandship集運算
我自己部ZX300用左2年, 粒電同當初好似冇乜分別
不過部機兩年我用得700幾個鐘, 比你參考下
有閒錢就揀個快少少嘅速遞
之前揀免運費, 佢同我由new york開始搭貨車搭到去portland
等左差唔多半個月先到buyandship個倉
之前揀免運費, 佢同我由new york開始搭貨車搭到去portland
等左差唔多半個月先到buyandship個倉