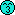
家用NAS/Server/Homelab集中討論區(5)
極北鷲
992 回覆
18 Like
2 Dislike
真係可以咁?
有d舖會
佢會肯收price個價,但要你響price app度落單,佢就響公司account度收單
(我唔太知咁做佢公司有咩好處,類似uber gogovan刷評分咁樣?)
佢會肯收price個價,但要你響price app度落單,佢就響公司account度收單
(我唔太知咁做佢公司有咩好處,類似uber gogovan刷評分咁樣?)

218J 同223J 粒U差得遠唔遠?
想買部黎做 remote hyperbackup
差400諗緊買新定舊
想買部黎做 remote hyperbackup
差400諗緊買新定舊
另外有冇人試過router 做FTP server 比 remote hyperbackup
我Asus router set完連唔到
我Asus router set完連唔到
唔知你外國住到有幾偏僻,條頻寬有幾慢,有冇試過upload 去大公司 cloud 例如 google drive / ms onedrive / dropbox ,如果都係咁慢就即係你酒店出街條公廁水喉太慢。一係就等當地凌晨,其他住客瞓晒唔係用緊時先至用
如果 cloud 快,得屋企慢,咁就先 upload 去 cloud,再 remote 叫屋企隻 NAS 直接由 cloud 再 download,咁呢一步就唔使用到 hotel bandwidth,你朝早出去遊玩時佢慢慢抄都得
如果 cloud 快,得屋企慢,咁就先 upload 去 cloud,再 remote 叫屋企隻 NAS 直接由 cloud 再 download,咁呢一步就唔使用到 hotel bandwidth,你朝早出去遊玩時佢慢慢抄都得

HyperBackup支援FTP架咩?
事實上佢好似連SMB server都唔支援直隊過去,除非你rsync
事實上佢好似連SMB server都唔支援直隊過去,除非你rsync
我原本都諗住rsync先得
比呢個網fake左

咁可能買隻223J直接啲
比呢個網fake左
咁可能買隻223J直接啲
有冇人係LXC到用Docker/Podman?
見Proxmox官方唔推薦係LXC到行佢地
https://pve.proxmox.com/pve-docs/pve-admin-guide.html#chapter_pct
但有D app係只distribute docker版 好似自己撈source去build好D
好似自己撈source去build好D
btw研究左先知home assistant個內核係python program黎 裝曬D dependencies之後pip install homeassistant就得
裝曬D dependencies之後pip install homeassistant就得
見Proxmox官方唔推薦係LXC到行佢地
https://pve.proxmox.com/pve-docs/pve-admin-guide.html#chapter_pct
但有D app係只distribute docker版
好似自己撈source去build好Dbtw研究左先知home assistant個內核係python program黎
裝曬D dependencies之後pip install homeassistant就得我都用緊lxc 行docker. 因為我都係跟教學, 所以都照用算
新手唔係好理解RAID5既原理,上網睇過RAID5大約=RAID0+RAID1,但唔太明
例如我用3個4TB HDD行RAID5應該會有8TB用,當我打爆8TB既時DATA其實係點分佈可以令我係死左1隻HDD既時候可以有得救
例如我用3個4TB HDD行RAID5應該會有8TB用,當我打爆8TB既時DATA其實係點分佈可以令我係死左1隻HDD既時候可以有得救
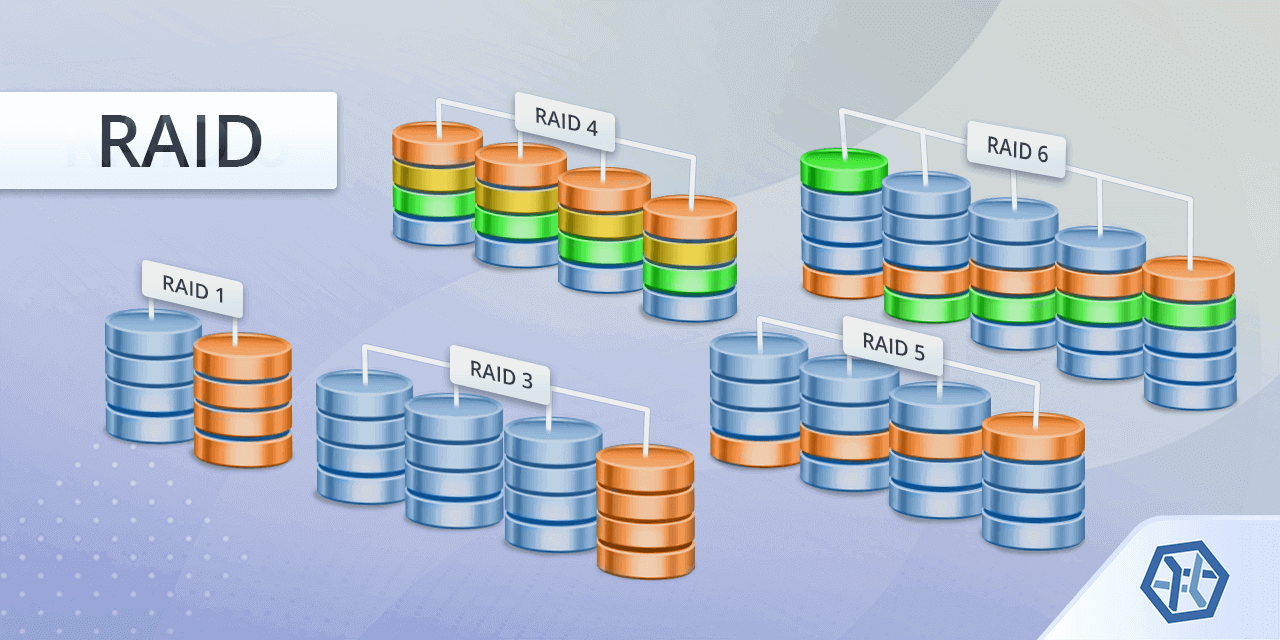
藍色係原裝data
橙色係鏡像 / redundancy
青色係再多一鏡
我諗最易理解係當RAID5係RAID1,但將嗰一舊鏡像打散做幾份去俾每隻分配
exactly一碟一份,只要你只死一隻碟,咁仲生還嗰幾隻碟就啱啱好砌得番100% data出嚟無野少咗
用返3隻4TB做例,可以用既容量8TB=100%,鏡像=200%=16TB點可以將16TB分佈落只有12TB既空間
點可以將16TB分佈落只有12TB既空間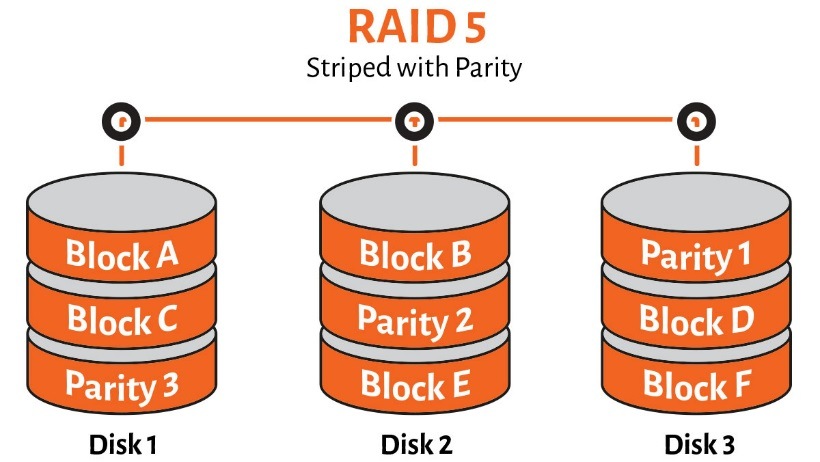
RAID5個套路係碟嘅數目越多,你「浪費」去做鏡嘅%就越少
三碟就係用咗1/3,唔需要1/2 (咁會係RAID1)
三碟各4TB RAID5情況下係咁
呢度分開做九份每份1.33GB
7.98GB本體data,3.99GB鏡像
以3隻碟嚟計,碟1同碟2 放data 嘅一半,而碟3 係放parity,你可以想像係身分證號碼嘅括弧咁,如果碟2 死,佢可以用數學運算嘅方法靠 碟1 + 碟3 去救返 碟2 嘅數據。如果碟1 死,都可以靠 碟2 + 碟3 計返碟1 嘅數據,如此類推
咁更加聰明嘅設計就係唔好全部用晒碟3嚟放 parity data,就好似上圖橙色部分咁,實際上parity data 都係打散咁平均分佈3隻碟。總之死碟情況,佢死任何一隻碟都仲救得返,唔好死多過一隻就得。而平時使用情況,可以碟1 同 碟2 一齊讀同寫,就做到 RAID 0 嘅 雙倍讀寫 速度
咁更加聰明嘅設計就係唔好全部用晒碟3嚟放 parity data,就好似上圖橙色部分咁,實際上parity data 都係打散咁平均分佈3隻碟。總之死碟情況,佢死任何一隻碟都仲救得返,唔好死多過一隻就得。而平時使用情況,可以碟1 同 碟2 一齊讀同寫,就做到 RAID 0 嘅 雙倍讀寫 速度
就係唔明點解3.99TB晚鏡像可以修復到7.98TB既DATA
sor for 1999,「上圖」係指#490 幅圖,藍色係數據,橙色係儲「身分證嘅括號」
即係parity data其實唔係我放入HDD既DATA,而係用於修復計算既DATA
上面巴打回咗,「可以想像係身分證號碼嘅括弧咁」
如果你想再理解得深d,佢實際上係大概咁做:
「將其他碟嗰個block嘅總和加埋係單定雙數」
咁做就只需要一鏡咁多parity容量
如果你手上只有呢一舊data,你係咩都修復唔到出嚟
RAID rebuild就係聰明地用呢一舊野,再對照番未死嗰幾隻碟內有嘅data,加埋如果對數就係1,唔對數就係0,go through完晒全部block之後就完整砌得番死撚咗嗰一抽data出嚟
如果你想再理解得深d,佢實際上係大概咁做:
「將其他碟嗰個block嘅總和加埋係單定雙數」
咁做就只需要一鏡咁多parity容量
如果你手上只有呢一舊data,你係咩都修復唔到出嚟
RAID rebuild就係聰明地用呢一舊野,再對照番未死嗰幾隻碟內有嘅data,加埋如果對數就係1,唔對數就係0,go through完晒全部block之後就完整砌得番死撚咗嗰一抽data出嚟
你可以咁諗,其實呢個係 RAID 0 同 RAID 1 之間取平衡
RAID 0 讀寫快(單碟)一倍,但係死碟機會都快一倍(理論上任何機械嘅嘢都有設計壽命,如果兩隻碟一齊各讀/寫一半 data,數學上死得快過你單機隻碟)
RAID 1 讀得快,寫就(同單碟)一樣,而更大嘅唔好處係$$$,你兩隻4TB嘅錢先買到一隻4TB嘅空間儲嘢
咁 RAID 5 就係又有RAID 0 嘅優點而又喺($$$ per TB) 上比 RAID 1 優勝
RAID 0 讀寫快(單碟)一倍,但係死碟機會都快一倍(理論上任何機械嘅嘢都有設計壽命,如果兩隻碟一齊各讀/寫一半 data,數學上死得快過你單機隻碟)
RAID 1 讀得快,寫就(同單碟)一樣,而更大嘅唔好處係$$$,你兩隻4TB嘅錢先買到一隻4TB嘅空間儲嘢
咁 RAID 5 就係又有RAID 0 嘅優點而又喺($$$ per TB) 上比 RAID 1 優勝
因為係成個 pool 一齊 contribution to rebuild,唔係就咁 parity 就修復到
RAID 簡單啲嚟講就係 XOR opreation
舉個好簡化嘅例子,例如一個 3 disk pool :
Disk 1: [000]
Disk 2: [001]
Disk 3: [001](parity)
假如 disk 2 瓜咗,000 XOR 001 = 001 就修復到返啲 data 出嚟。
所以 3TB*3 pool,係用緊 6TB 嘅 data 嚟 build 3TB 嘅 data
RAID 簡單啲嚟講就係 XOR opreation
舉個好簡化嘅例子,例如一個 3 disk pool :
Disk 1: [000]
Disk 2: [001]
Disk 3: [001](parity)
假如 disk 2 瓜咗,000 XOR 001 = 001 就修復到返啲 data 出嚟。
所以 3TB*3 pool,係用緊 6TB 嘅 data 嚟 build 3TB 嘅 data
雖然 RAID5 實際上嘅 implementation 係將 parity 平均咁分散儲存喺唔同嘅碟上,但係原理係差唔多。