但睇唔明你堆野

 你可以先 review 咗 linear algebra + optimization 然後再望返呢個 post. 因為 householder transform 對 undergrad 嚟講都算 advanced, 小妹有諗住 skip 埋呢 part, 但 skip 咗就好似 black box 咗 QR factorization 嘅原理
你可以先 review 咗 linear algebra + optimization 然後再望返呢個 post. 因為 householder transform 對 undergrad 嚟講都算 advanced, 小妹有諗住 skip 埋呢 part, 但 skip 咗就好似 black box 咗 QR factorization 嘅原理






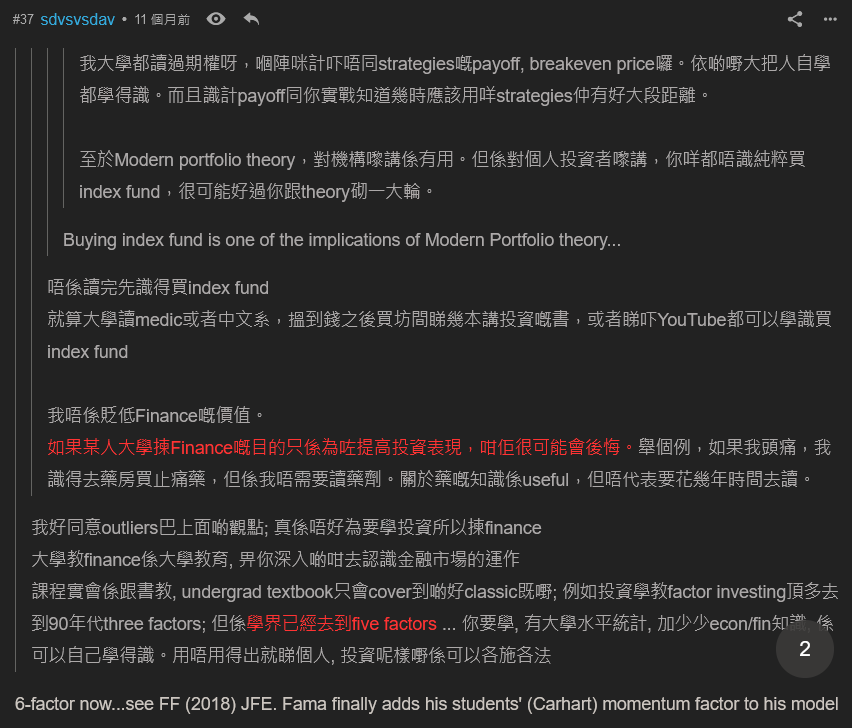
 點都唔夠 sdv 乜鳩柒咁無知以為先計 inv(Gram(X)) 再乘 X'*y 咁蠢, 唔識數學又喺度出風頭又唔敢自己開 post
點都唔夠 sdv 乜鳩柒咁無知以為先計 inv(Gram(X)) 再乘 X'*y 咁蠢, 唔識數學又喺度出風頭又唔敢自己開 post 比 sdv 唔識串騎劫咗啦, 咁多嘢講唔自己開 post 嘅廢物, 我懷疑佢連 svd 同埋計 inverse 要用幾多 flops 都唔知 不如你教下我 inverse matrix 計咗係邊啦 然後專門 mon 住 econ/stat post 嚟 show-off, 點解唔敢自己開 post 呢? 因為佢連 linear algebra 都搞唔掂
比 sdv 唔識串騎劫咗啦, 咁多嘢講唔自己開 post 嘅廢物, 我懷疑佢連 svd 同埋計 inverse 要用幾多 flops 都唔知 不如你教下我 inverse matrix 計咗係邊啦 然後專門 mon 住 econ/stat post 嚟 show-off, 點解唔敢自己開 post 呢? 因為佢連 linear algebra 都搞唔掂 留名跟 sdv...連名都打唔好嘅人學嘢, 佢好似連 general 嘅 neural network 同埋 feedforward network 都未分清, 以為 neural network = multilayer 嘅 logistic regression.
留名跟 sdv...連名都打唔好嘅人學嘢, 佢好似連 general 嘅 neural network 同埋 feedforward network 都未分清, 以為 neural network = multilayer 嘅 logistic regression. 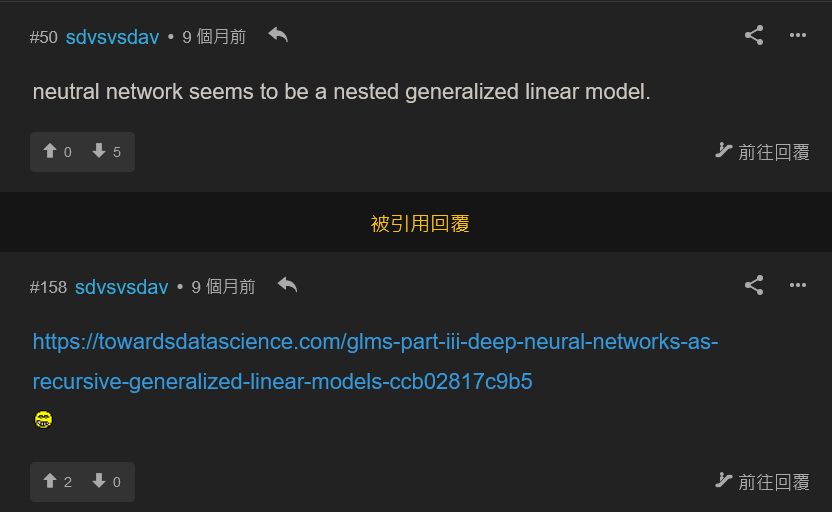 究竟喺一個 Boltzmann machine 點樣 "seems to be a nested generalized linear model" ? 小妹就係真係唔明啦, 不過好明顯佢唔係 stat/ml 嘅 practitioner
究竟喺一個 Boltzmann machine 點樣 "seems to be a nested generalized linear model" ? 小妹就係真係唔明啦, 不過好明顯佢唔係 stat/ml 嘅 practitioner 連 GLM 都學唔好都夠膽 mon 住連登 stat post 喺度泥漿摔角?
連 GLM 都學唔好都夠膽 mon 住連登 stat post 喺度泥漿摔角? 如果正經討論冇乜所謂, 佢係嗰種孔乙己 type
如果正經討論冇乜所謂, 佢係嗰種孔乙己 type 
 好似啲亞氏保加症兒童咁
好似啲亞氏保加症兒童咁