python Csv問題
無糖零可樂
256 回覆
0 Like
55 Dislike
佢個係唔係只加入5000?
df = pd.DataFrame({f"col{i}":np.random.randint(1, 10, 10) for i in range(8)})
df[8] = df.index+5000
print (df)
col0 col1 col2 col3 col4 col5 col6 col7 8
0 1 3 7 7 6 7 5 7 5000
1 4 5 5 1 4 4 2 6 5001
2 7 5 8 1 7 1 4 1 5002
3 2 1 7 3 6 4 3 1 5003
4 7 8 8 8 7 6 9 9 5004
5 4 5 8 2 8 3 5 5 5005
6 6 5 6 8 3 1 5 3 5006
7 5 3 3 9 1 4 1 9 5007
8 8 8 4 3 8 7 7 9 5008
9 6 5 1 3 3 7 1 8 5009Always take advantage of vectorized methods!
咁如果我想任意改由其他值開始
例如400
AA=400
df.index+AA
咁得唔得?
例如400
AA=400
df.index+AA
咁得唔得?
當然可以。
一個好重要既concept係numpy broadcasting。假設你有一個np.array:
當你進行scalar運算果陣,numpy會嘗試自動broadcast去match返個dimension,所以如果你將a+2,答案會喺
同樣既concept會apply落pandas度,因為pandas喺based on numpy。所以如果你想抽一行column出嚟做運算,答案亦會base on index或自動broadcast。
如果解得唔清楚好抱歉,呢啲concept比較難用中文打出嚟。
一個好重要既concept係numpy broadcasting。假設你有一個np.array:
a = np.array([1,2,3,4,5])當你進行scalar運算果陣,numpy會嘗試自動broadcast去match返個dimension,所以如果你將a+2,答案會喺
[3 4 5 6 7]
.同樣既concept會apply落pandas度,因為pandas喺based on numpy。所以如果你想抽一行column出嚟做運算,答案亦會base on index或自動broadcast。
如果解得唔清楚好抱歉,呢啲concept比較難用中文打出嚟。
我唔知我有冇理解錯誤
意思係如果我想獨立一個col做運算
就要抽佢出嚟?
因為我而家嘅諗法係
User可以決定係4000定5000做開始
然後就每行就會順序咁加1
意思係如果我想獨立一個col做運算
就要抽佢出嚟?
因為我而家嘅諗法係
User可以決定係4000定5000做開始
然後就每行就會順序咁加1
其實你究竟唔明乜 有咩你自己試過唔work?
有咩你自己試過唔work?
有咩你自己試過唔work?佢似係咩都唔明
你地provide solutions 佢試完用到迷用
你地provide solutions 佢試完用到迷用
冇野唔work呀 麻煩晒
只不過我想知下個邏輯
因為我以為要用loop去做
只不過我想知下個邏輯
因為我以為要用loop去做
咁如果我想col8大過6000就變番5000
咁可唔可以就咁用if fd[8] = 6000:
去進行運算?
咁可唔可以就咁用if fd[8] = 6000:
去進行運算?
用得pandas基本上唔應該再諗咩for loop同iteration,你要loop既就用返普通dict/list etc
無論做乜,首選pandas built-in 或numpy vectorized methods,再唔得就custom function+list comprehension,再落就apply
如果想睇詳盡解釋,可以睇下呢個答案︰https://stackoverflow.com/questions/16476924/how-to-iterate-over-rows-in-a-dataframe-in-pandas/55557758#55557758
無論做乜,首選pandas built-in 或numpy vectorized methods,再唔得就custom function+list comprehension,再落就apply
如果想睇詳盡解釋,可以睇下呢個答案︰https://stackoverflow.com/questions/16476924/how-to-iterate-over-rows-in-a-dataframe-in-pandas/55557758#55557758
NO!
講左好多次,你唔係計緊一個數,係一行數
你個logic應該係︰由0數到1000就RESET,之後成行加5000
所以個計法應該係:
講左好多次,你唔係計緊一個數,係一行數
你個logic應該係︰由0數到1000就RESET,之後成行加5000
所以個計法應該係:
df.index%1000+5000明白
咁如果我想只print col8既最後一個data
係唔係要用其他方法?
係唔係要用其他方法?
原來只要 df.iloc[-1:,8]就得
多謝大佬指教
多謝大佬指教
你用df.iloc[-1:,8] 只會攞到有一個value既pd.Series:
如果想提取其中一個cell既value,用iat:
9 5009
Name: 8, dtype: int64
<class 'pandas.core.series.Series'>如果想提取其中一個cell既value,用iat:
df[8].iat[-1]
5009 兩者既分別係?
咪一個係pd.Series,另一個係純int
你攞得最後一個value都想直接用㗎啦,如果係Series你又要另外index個value出嚟
你攞得最後一個value都想直接用㗎啦,如果係Series你又要另外index個value出嚟
因為我想個exe比win xp既機用
所以我係第二部機裝左pandas 0.20.1
但之後就run唔到
係唔係用啲舊既code
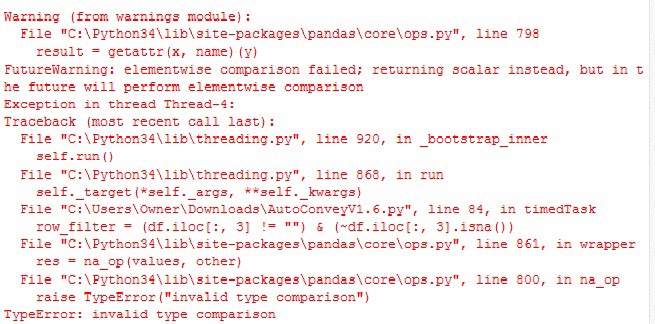
所以我係第二部機裝左pandas 0.20.1
但之後就run唔到
係唔係用啲舊既code
出到1.1x喇喎,做咩要裝0.20? 有咩特別?
我上裝睇啲教學講既
咁我係唔要del 左pandas 0.20佢?
之後再裝新?
同我應該裝邊個
咁我係唔要del 左pandas 0.20佢?
之後再裝新?
同我應該裝邊個
因為新既版本 係windows xp 用唔到
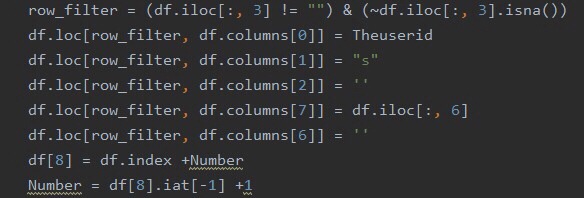
用新既版本係正常run到
我都係分開兩個exe咁用啦
麻煩晒 大佬
同我想問下如果我想兩個csv做對比
會唔會好難?
麻煩晒 大佬
同我想問下如果我想兩個csv做對比
會唔會好難?
睇你compare乜。如果column同index一樣,齋數值唔同,可以直接compare by df1 == df2
首先係兩個唔同既csv
T1.csv
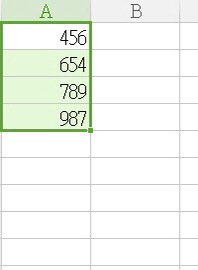
T2.csv
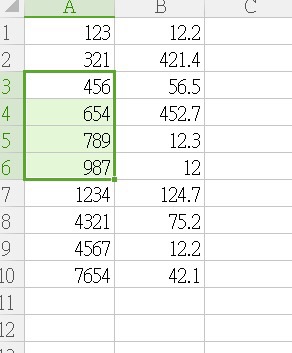
我想如果T1 既col1 值 同T2 既col1相同時
T1既col2就會copy左T2既col2值
T1.csv
T2.csv
我想如果T1 既col1 值 同T2 既col1相同時
T1既col2就會copy左T2既col2值