呢個可以算係monte carlo simulation
不過冇Markov chain, 通常係你要generate個d random sample本身係好難直接describe到先要用個Markov chain黎gen
樓主呢個example本身個setting夠簡單其實有closed-form formula:
中獎率p既話抽n次中k次既機率係: (n choose k)*p^k*(1-p)^(n-k)
平均中獎次數係: n*p
variance係: n*p*(1-p), standard deviation係sqrt(n*p*(1-p))
n = 500, p = 0.0316時個平均數係15.8, 而你sim出黎同sample夠多時會好接近因為law of large number
sd係3.9116
事實上本身個distribution係binomial, 我估R入面應該就有d function可以直接用黎睇binomial distribution
Btw, 我唔知R會唔會自動parallelize d loop (如果發覺冇咩data dependency既話)
一般黎講loop本身係好sequential既operation, 有data dependency既時候parallelize唔到 (你當係用唔到GPU或者multi-thread, 或者難d用到)
所以呢個example黎講可能你直接gen一個length 100萬既vector, 每格係uniform distribution in [0, 1], 之後再睇返個binomial distribution既cdf轉返d entry做中獎次數
咁既話可能會快d因為d operation都可以run in parallel
[大數據分析]深入淺出地教你用分析軟件R-Studio
科學怪人
374 回覆
149 Like
2 Dislike
我會繼續努力💪🏻
好有用呀 一步一步跟緊樓主學野
用開 SAS
我就係要依啲高質討論
多謝巴打提醒咗我
要解以上遊戲嘅問題原來仲有兩個方法
而且R係做得到
多謝巴打提醒咗我
要解以上遊戲嘅問題原來仲有兩個方法
而且R係做得到
講完data.frame之後自然要講apply
練習5
之前都一次過講咗if switch for之類
但依啲都好需要實戰先會明
童年回憶 - 大富翁3
當中賭場嘅遊戲就叫做骰寶
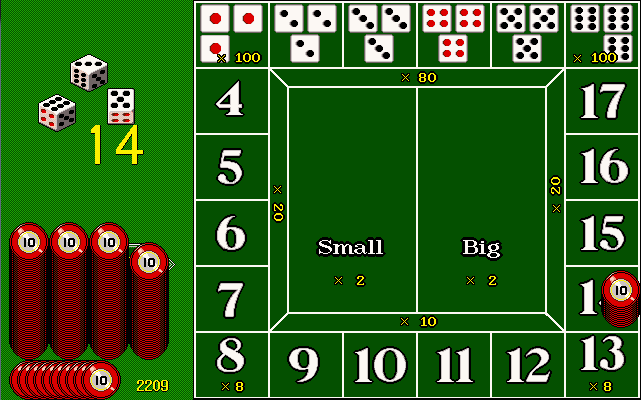
買大細係1蚊中咗變2蚊,不設圍骰通殺
擲三粒骰嘅總和點數,就分別係:
4-7: 1變20
8,13: 1變8
9-12: 1變10
圍骰:圍1、6 則1變100,其他80
試透過R分析必勝之法
註:依一個版本嘅賠率當然同真實有分別
不然怎麼叫十賭九輸
之前都一次過講咗if switch for之類
但依啲都好需要實戰先會明
童年回憶 - 大富翁3
當中賭場嘅遊戲就叫做骰寶
買大細係1蚊中咗變2蚊,不設圍骰通殺
擲三粒骰嘅總和點數,就分別係:
4-7: 1變20
8,13: 1變8
9-12: 1變10
圍骰:圍1、6 則1變100,其他80
試透過R分析必勝之法
註:依一個版本嘅賠率當然同真實有分別
不然怎麼叫十賭九輸
落注係點買法?
例如係買加埋4-7, 中左就20倍
定4-7係分開買?即係我買4但係開7就冇賠
例如係買加埋4-7, 中左就20倍
定4-7係分開買?即係我買4但係開7就冇賠
分開買
用10點券買4 ,如三粒骰總和係4,贏咗會收返200點券
但如果開出總和唔係4都作負論
用10點券買4 ,如三粒骰總和係4,贏咗會收返200點券
但如果開出總和唔係4都作負論
必勝係in咩sense? Expected return?
睇worst case應該做唔到必勝:
首先worst case要全部圍骰買齊, 4-10一係買齊一係買細, 11-17一係買齊一係買大
要worst case return有1既話圍1圍6要各買1/100最少, 圍2-5各買1/80
同樣idea黎比較買細定買齊4-10好d既話
suppose開出黎係細,all in細return係2, 買齊4-10既話要有同樣worst case return要4-7各買最少2/20, 8買2/8, 9-10各買2/10, 加埋要買1.05, 所以直接買細會好d
之後要有賺既話大細要各買1/2, 加埋要有1/2+1/2+2/100+4/80 = 1.07本但只係賠1
所以應該就冇worst case必勝法
如果係in expectation, return > 1既話可以睇做linear program:
max p_1*x_1+p_2*x_2+...+p_22*x_22
subject to: x_1+...+x_22 = 1
x_1, ..., x_22 >= 0
LP既optimal solution一定係attained at some extreme point, 所以optimal strategy一定係買死其中一個
之後計下d probability, 各圍骰出現機率各1/6^3 = 1/216, 所以可以唔買
加埋係3-18出現既probability可以計[1/6 ... 1/6] convolve自己3次, 結果係
[0.0046 0.0139 0.0278 0.0463 0.0694 0.0972 0.1157 0.1250 0.1250
0.1157 0.0972 0.0694 0.0463 0.0278 0.0139 0.0046]
所以買死7, 9, 10, 11, 12, 14都會有賺, expected return分別係
1.388, 1.157, 1.25, 1.25, 1.157同1.388
optimal strategy係次次都買7或者14
睇worst case應該做唔到必勝:
首先worst case要全部圍骰買齊, 4-10一係買齊一係買細, 11-17一係買齊一係買大
要worst case return有1既話圍1圍6要各買1/100最少, 圍2-5各買1/80
同樣idea黎比較買細定買齊4-10好d既話
suppose開出黎係細,all in細return係2, 買齊4-10既話要有同樣worst case return要4-7各買最少2/20, 8買2/8, 9-10各買2/10, 加埋要買1.05, 所以直接買細會好d
之後要有賺既話大細要各買1/2, 加埋要有1/2+1/2+2/100+4/80 = 1.07本但只係賠1
所以應該就冇worst case必勝法
如果係in expectation, return > 1既話可以睇做linear program:
max p_1*x_1+p_2*x_2+...+p_22*x_22
subject to: x_1+...+x_22 = 1
x_1, ..., x_22 >= 0
LP既optimal solution一定係attained at some extreme point, 所以optimal strategy一定係買死其中一個
之後計下d probability, 各圍骰出現機率各1/6^3 = 1/216, 所以可以唔買
加埋係3-18出現既probability可以計[1/6 ... 1/6] convolve自己3次, 結果係
[0.0046 0.0139 0.0278 0.0463 0.0694 0.0972 0.1157 0.1250 0.1250
0.1157 0.0972 0.0694 0.0463 0.0278 0.0139 0.0046]
所以買死7, 9, 10, 11, 12, 14都會有賺, expected return分別係
1.388, 1.157, 1.25, 1.25, 1.157同1.388
optimal strategy係次次都買7或者14
lm
所以買死7, 9, 10, 11, 12, 14都會有賺, expected return分別係
1.388, 1.157, 1.25, 1.25, 1.157同1.388
optimal strategy係次次都買7或者14
這就是我想要嘅方向

每一局都買依6個有正增值嘅數字
效果最快、賺錢最穩
留名
留名學野
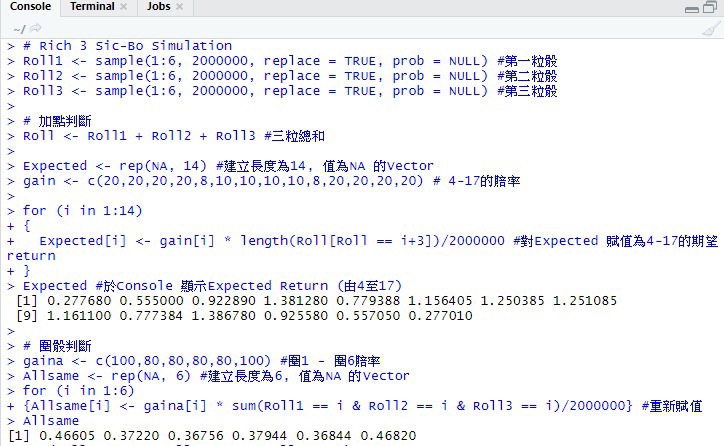
我做咗加總同圍骰嘅分析

模擬開彩2000000次結果並作出整理
頭3句唔駛解,都係1至6
三個同等長度嘅vector ,係可以簡單地按照對應位置逐一相加,變成另一個vector
之後,將對應4-17賠率入落gain
建立一個長度為14嘅「吉vector」準備對位入數
公式係
expected return = gain x probability
而vector Roll內可以進行條件選項,只抽取當中符合條件嘅
再用length 睇有幾多個項目符合條件
從而得到概率 再計算expected return
依個數字代表每買1蚊,長遠嚟講會得到嘅錢
所以我一定會喺7 9 10 11 12 14 各放押注
圍骰計法同理,從略
模擬開彩2000000次結果並作出整理
頭3句唔駛解,都係1至6
三個同等長度嘅vector ,係可以簡單地按照對應位置逐一相加,變成另一個vector
之後,將對應4-17賠率入落gain
建立一個長度為14嘅「吉vector」準備對位入數
公式係
expected return = gain x probability
而vector Roll內可以進行條件選項,只抽取當中符合條件嘅
再用length 睇有幾多個項目符合條件
從而得到概率 再計算expected return
依個數字代表每買1蚊,長遠嚟講會得到嘅錢
所以我一定會喺7 9 10 11 12 14 各放押注
圍骰計法同理,從略
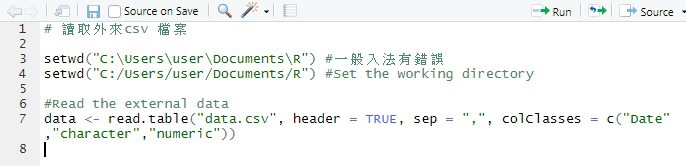
講下點樣基本處理外來嘅檔案啦
R支援csv 格式嘅數據檔案
所謂csv 即係comma-separated values
我個檔案叫data.csv
"Date","Type","Oil and Grease"
"2019-08-01",CS,45
"2019-08-01",FE,8
"2019-08-01",RW,0.5
"2019-08-04",CS,42
"2019-08-04",FE,6
"2019-08-07",CS,51
"2019-08-07",FE,9
"2019-08-07",RW,0.2
"2019-08-10",CS,62
"2019-08-10",FE,4
"2019-08-13",CS,58
"2019-08-13",FE,7
"2019-08-13",RW,1.4
"2019-08-16",CS,44
"2019-08-16",FE,6
"2019-08-19",CS,40
"2019-08-19",FE,8
"2019-08-19",RW,0.6
"2019-08-22",CS,69
"2019-08-22",FE,6
"2019-08-25",CS,32
"2019-08-25",FE,5
"2019-08-25",RW,3.1
"2019-08-28",CS,48
"2019-08-28",FE,4
"2019-08-31",CS,43
"2019-08-31",FE,6
"2019-08-31",RW,0.8
一般常見嘅字元同日期會有引號括住
每一個column 會以逗號分隔
每一個row 就會新開一行
依類檔案主要嘅優點係
1. 可以簡單地用記事本建立同修改
2. 適用於任何數據處理程式
結果
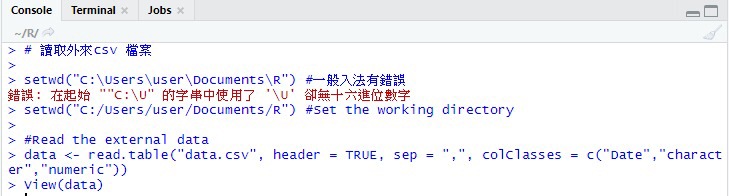
當涉及外來檔案嘅處理
首先要用setwd 指令將個檔案嘅folder 話俾R聽
跟住就可以配合read.table指令
留意要喺R儲存外間內容,都要透過對R嘅物件賦值
read.table 裏面,首先要檔案名
之後參數:
header 標題,TRUE就代表個file第一行係標題
sep = “,” 表示csv檔
colClasses 定義由左至右每一個column嘅資料類別
之後用View 指令可以睇到個data
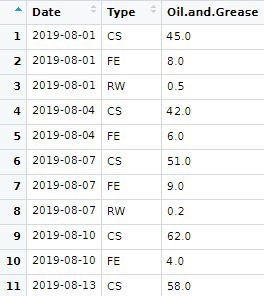
依個data性質係data.frame
如果話單一數值係點,vector係線
data.frame就係由多個vector 組成嘅面
每一個column 代表一個vector
R支援csv 格式嘅數據檔案
所謂csv 即係comma-separated values
我個檔案叫data.csv
"Date","Type","Oil and Grease"
"2019-08-01",CS,45
"2019-08-01",FE,8
"2019-08-01",RW,0.5
"2019-08-04",CS,42
"2019-08-04",FE,6
"2019-08-07",CS,51
"2019-08-07",FE,9
"2019-08-07",RW,0.2
"2019-08-10",CS,62
"2019-08-10",FE,4
"2019-08-13",CS,58
"2019-08-13",FE,7
"2019-08-13",RW,1.4
"2019-08-16",CS,44
"2019-08-16",FE,6
"2019-08-19",CS,40
"2019-08-19",FE,8
"2019-08-19",RW,0.6
"2019-08-22",CS,69
"2019-08-22",FE,6
"2019-08-25",CS,32
"2019-08-25",FE,5
"2019-08-25",RW,3.1
"2019-08-28",CS,48
"2019-08-28",FE,4
"2019-08-31",CS,43
"2019-08-31",FE,6
"2019-08-31",RW,0.8
一般常見嘅字元同日期會有引號括住
每一個column 會以逗號分隔
每一個row 就會新開一行
依類檔案主要嘅優點係
1. 可以簡單地用記事本建立同修改
2. 適用於任何數據處理程式
結果
當涉及外來檔案嘅處理
首先要用setwd 指令將個檔案嘅folder 話俾R聽
跟住就可以配合read.table指令
留意要喺R儲存外間內容,都要透過對R嘅物件賦值
read.table 裏面,首先要檔案名
之後參數:
header 標題,TRUE就代表個file第一行係標題
sep = “,” 表示csv檔
colClasses 定義由左至右每一個column嘅資料類別
之後用View 指令可以睇到個data
依個data性質係data.frame
如果話單一數值係點,vector係線
data.frame就係由多個vector 組成嘅面
每一個column 代表一個vector
巴打講吓apply, 識apply代替loop會快好多
big data 好似有好多definition ,IT點睇big data?Tb算唔算?定Pb先算?
R data到 50Gb左右就會好明顯咁慢落嚟.
R data到 50Gb左右就會好明顯咁慢落嚟.
有用開python,留名
睇嚟你對R 既background data storage唔係好識
巴打個3骰總和既distribution可以直接計
in general given random variables X, Y
X+Y既distribution係X同Y既distribution既convolution
let dist = [1/6 1/6 1/6 1/6 1/6 1/6], 可以直接計dist*dist*dist (呢度"*"代表convolution)
R照計應該有呢個做built-in function
convolution呢個operation即係d人做signal processing時apply filter呢個operation
例如你想blur幅圖,實際上係計幅圖同個filter既convolution (2d version)
將兩個polyomials乘埋其實都係做緊convolution
另外convolution可以計得好快,因為有Fast Fourier Transform
所以除非個random variable既possible outcome數差唔多有sample數咁多
直接計convolution會快d
in general given random variables X, Y
X+Y既distribution係X同Y既distribution既convolution
let dist = [1/6 1/6 1/6 1/6 1/6 1/6], 可以直接計dist*dist*dist (呢度"*"代表convolution)
R照計應該有呢個做built-in function
convolution呢個operation即係d人做signal processing時apply filter呢個operation
例如你想blur幅圖,實際上係計幅圖同個filter既convolution (2d version)
將兩個polyomials乘埋其實都係做緊convolution
另外convolution可以計得好快,因為有Fast Fourier Transform
所以除非個random variable既possible outcome數差唔多有sample數咁多
直接計convolution會快d
唔識
shiny / plotly / leaflet / rbokeh / trelliscope 已經至少已經5個
你無記錯,不過認識唔夠高
你無記錯,不過認識唔夠高