深度人工網路
大家可能已經聽過deep learning深度學習呢隻字,其實呢樣野好簡單,就係多過一層的ANN架構,已經可以叫做深度人工網路

好多人會覺得,如果你層數愈多,咁個network咪愈準?
世上無免費的午餐,雖然大體上概念真係愈多層,預測真係會愈準,但係實際執行上,會有好多既問題出現
單睇一層既ANN架構,如果input係m咁多個,有k咁多個人工神經元,輸出返n咁多個output,咁總連結數就係m*n*k咁多個組合,係咁既情況之下,就算ANN幾十年前已經被design出來,就算去到今日既大型電腦,都唔係好計算到咁大既量級data
樓上呢個連接方式,又叫全連接(Fully Connect), 係現代既DL架構入面,一般只係classifier最後一層先會用。由於呢個過程相等於vector martix既inner product,所以又有人叫inner product layer。成個DL既架構又有人會叫
Fully Connected Neural Network (FNN)
有另一隻neural network又係叫FNN, 全名係Feedforward Neural Network, 但係Convolution Neural Network都係後者之一, 所以FNN呢隻字都較為少見,又或者有人叫FC-ANN, fully connected artificial neural network,不過都只係名來的

呢種最簡單既ANN有個好大的問題,就係input layer既大小唔可以改變,咁樣對於唔同大小既影像/矩陣輸入就會好有侷限性
網路深度增加時的問題
傳統ANN最大既問題,就係深度增加時,除左訓練時間會增加之外,仲有一個好大的問題就係梯度消失問題(Vanishing Gradient Problem)同Overfitting問題
梯度消失
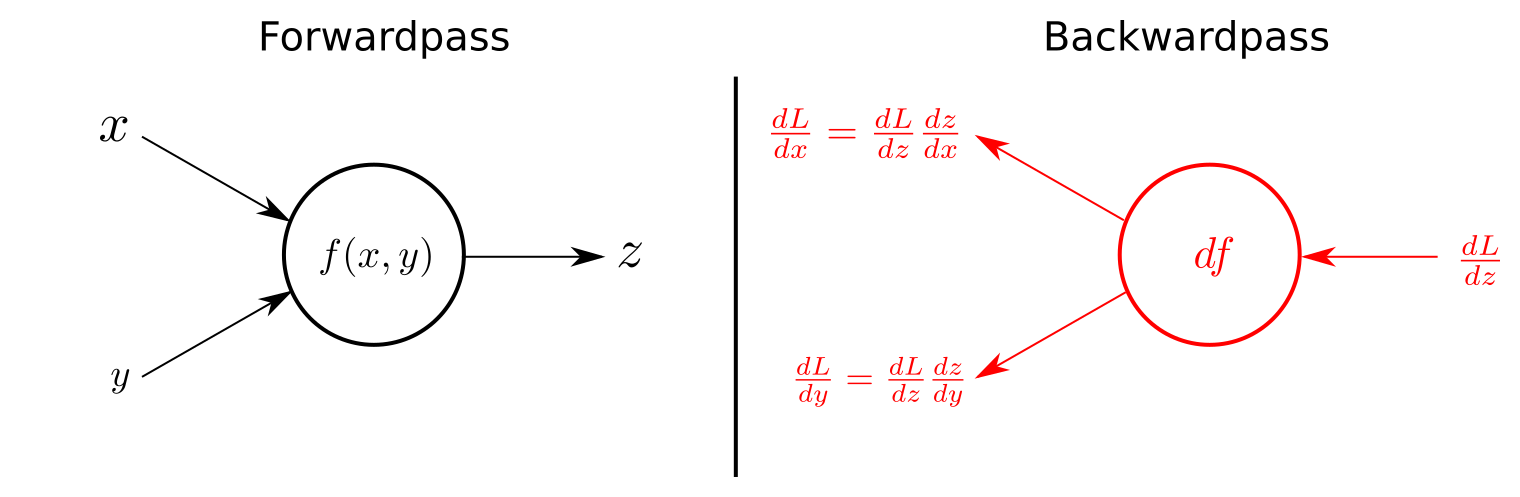
幾個chapter之前講過,ANN既訓練係靠SGD等反向傳遞去做optimization,而SGD既計算實際上係每一個neuron output得出誤差值後,用條activation function同hidden layer的微分值去得出修正值
淺層既ANN還好, SGD後去返input layer個修正數字仲有返咁上下大細,但深度達到N層既ANN架構,做反向傳遞就要微分N次咁多,即係話,有可能去到一半果陣個gradient 就會變曬0,成個network根本就訓練唔到
vanshing gradient可以用ReLU呢條activation function去改善,因為呢條function個微分值會大過sigmoid function係同一位置既微分值,不過深度增加後仍然有同樣問題出現
過擬合
Overfitting問題係指我地拎data訓練時,由於過度既訓練,導致訓練結果有偏差

利用過分深層既ANN做訓練,如果相應既training set 唔夠大的話,你好容易就會fit過龍
簡單的例子:
如果你要電腦學一張紙既特徵,但你得10張相,你又係咁叫部電腦自己係呢10張相中搵出"紙"既特徵,佢好有可能連張紙旁邊既筆呀間尺呀人呀都學埋入去個Network度
而點樣可以避免overfitting問題,之後講residual block果陣會講下新既NN有咩方式處理







