
阿里巴巴發布 Qwen-Image,主打在理解文字語境後直接生成影像,試圖縮短「說了什麼」與「畫出什麼」之間的差距。以簡單描述「黃昏時一條有霧的街道,路旁有紙燈籠」為例:Stable Diffusion 會依照這句話一步步從模糊構圖去噪,最終生成符合關鍵字但細節可能顯得拼貼、燈籠和霧的關聯性較弱;Qwen-Image 則據稱在語言與畫面同時處理下,能更自然地把「紙燈籠在霧中發光、黃昏光線漫開」融合成一張整體感強的畫面。
與 Stable Diffusion 相比,Qwen-Image 不是把文字當作外掛條件再「照譜」作畫,而是更像邊聽敘述邊即時調整畫面的廚師,讓語境中的關係(如「霧讓燈光柔化」)自動體現在影像之中。


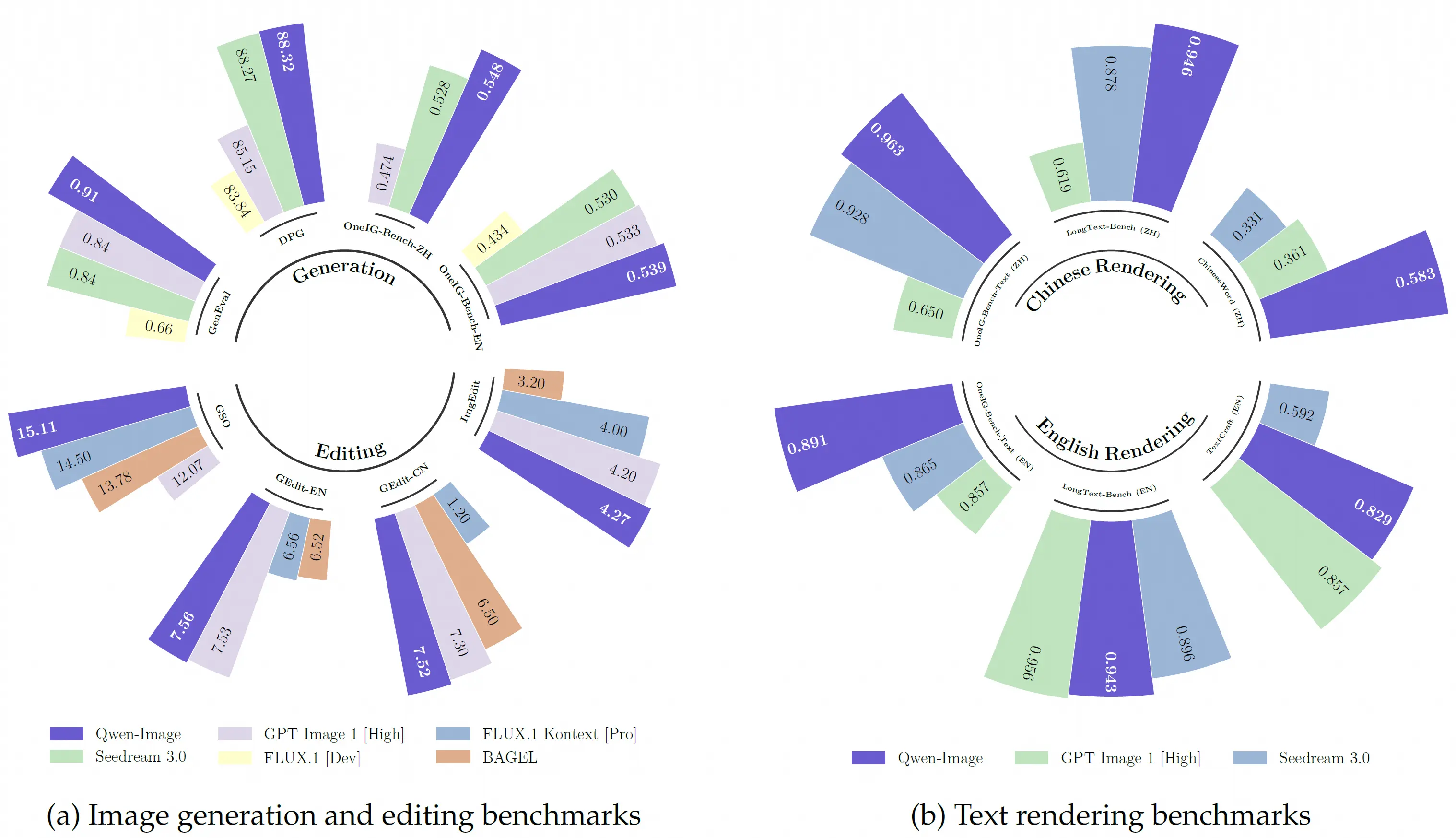
在處理影像中包含文字的情況下,傳統擴散模型如 Stable Diffusion 仍普遍表現不佳,字母扭曲、錯位或出現非語義亂碼,是因為這類模型學習的是整體圖樣的統計特徵而非精確的符號結構,缺乏對字形、間距、字體規則的內建理解,導致「在圖裡畫清楚一段文字」變成難題。反觀 Qwen 系列在多模態理解上強調語言與視覺的共同建模(如 Qwen VLo 的說明),此一架構理論上能讓文字作為語義的一部分被更準確嵌入圖中,而不是外加條件式地後置包裹,對於「圖中要有清晰可讀的文字」這類需求有潛在改善空間(但具體實作細節尚未完全公開)。






