在深入探討超級智能人才競爭之前,我們應回顧Meta如何陷入這一尷尬境地。在以Llama 3引領開源前沿後,Meta如今落後於中國的DeepSeek。
在技術層面,我們認為失敗的主要原因包括:
• 分塊注意力機制
• 專家選擇路由
• 預訓練數據質量
• 擴展策略與協調
分塊注意力
大型語言模型的注意力機制若簡單實現,隨令牌數量呈二次方增長。為解決此問題,研究人員引入了內存高效機制。Meta為Behemoth選擇了分塊注意力,這可能是一個錯誤。雖然內存效率提高,允許更長的上下文,但代價是每個塊的首個令牌無法訪問之前的上下文。儘管有一些全局注意力層,但這不足以應對長範圍推理。
其他模型使用的滑動窗口注意力提供了更平滑的替代方案:注意力窗口逐個token向前滑動,保持局部連續性,即使長範圍推理仍需多層傳播上下文。
Behemoth的分塊注意力追求效率,卻在塊邊界造成盲點,影響模型在超過一個塊長度的思維鏈上的推理能力。模型難以進行長範圍推理。雖然這在事後看來顯而易見,但我們認為問題之一是Meta缺乏適當的長上下文評估或測試基礎設施,無法確定分塊注意力不適用於推理模型的開發。Meta在強化學習和內部評估上遠遠落後,但新挖角的員工將大幅縮小推理差距。
專家選擇路由
大多數現代大型語言模型採用專家混合(MoE)架構,在每個模型層之間,根據路由器將令牌分配給不同專家。在現代MoE模型中,大多數採用令牌選擇路由進行訓練,即路由器生成一個T x E形狀的張量(T為總令牌數,E為MoE模型中的專家數),並在E維度上運行topK softmax,生成T x K張量。這意味著路由器為每個令牌T選擇K個最可能的專家,K可為一個或多個專家,K為研究者可調的超參數。
這種方法的優勢在於每個令牌保證由K個專家處理,確保每個令牌的信息價值被相同數量的專家吸收。缺點是某些專家可能過於「受歡迎」,而其他專家訓練不足,導致專家「智能」不平衡。這是一個已知的問題,許多頂尖實驗室通過輔助損失(或無損失)負載平衡解決了這一問題。在使用專家並行(EP)訓練時,這可能導致較低的訓練MFU,因為模型分佈在不同GPU節點上,導致更多跨規模網絡(InfiniBand或RoCE)的集合操作(NCCL),而非規模網絡(NVLink)。這是NVIDIA NVL72設計的主要動因,該設計將規模網絡擴展至超越標準8路服務器。
專家選擇路由由Google於2022年引入,顛倒了邏輯:專家選擇前N個token。對路由器生成的相同T x E張量,專家選擇路由在T維度上運行topN softmax,生成E x N張量。這意味著每個E專家選擇了N個最高概率的token進行路由。N超參數可由研究者調整,但與令牌選擇路由相比,N = K * T / E。
與token選擇路由直接比較,專家選擇路由保證專家以平衡方式激活,避免了不平衡專家的性能下降。需要明確的是:在兩種情況下,路由器均作出選擇。在token選擇中,路由器的輸入是token,選擇專家;在專家選擇中,輸入是專家,選擇token。
這平衡了專家訓練的負載,提升了分佈式硬件的MFU。超大規模網絡專為這種並行設計,我們在網絡模型中詳細探討。
這種方法的缺點與令牌選擇架構相反。專家選擇路由可能導致某些「受歡迎」的token被多個專家處理。雖然這不會產生令牌選擇路由中的訓練瓶頸,但可能導致模型泛化能力下降,因為LLM不再平等關注所有令牌。
主要的障礙在於推理。推理分為兩個步驟:預填充和解碼。在預填充階段,用戶提示被編碼並加載到KVCache,此步驟受Flop限制。在解碼階段,模型逐個token逐層計算注意力並運行前饋網絡。
專家選擇路由在這方面表現不佳,因為專家每層僅能從1個token x批次大小中選擇,導致每個專家獲得的token數量遠少於訓練時(例如訓練運行可能有8k序列長度x 16批次大小= 128k令牌每次傳遞)。現代GPU網絡的批次大小限制使得推理成本高昂且效率低下。
Meta在運行中途從專家選擇路由切換到token選擇路由,導致專家無法有效專精。
數據質量:自找的傷口
Llama 3 405B在15Ttoken上訓練,我們相信Llama 4 Behemoth需要大幅更多的token,約3-4倍數量級。獲得足夠高質量的數據是西方超大規模企業無法通過複製其他模型輸出的捷徑解決的主要瓶頸。
在Llama 4 Behemoth之前,Meta使用公開數據(如Common Crawl),但在運行中途轉向自建的內部網絡爬蟲。雖然這通常更優,但也適得其反。團隊難以清洗和去重新的數據流,這些流程未在大規模下接受壓力測試。
此外,與OpenAI和DeepSeek等所有其他領先AI實驗室不同,Meta未使用YouTube數據。YouTube講座筆錄和其他視頻是極佳的數據來源,公司在沒有這些數據的情況下可能難以開發多模態模型。
擴展實驗
除了上述技術問題,Llama 4團隊在將研究實驗擴展到完整訓練運行時也遇到困難。存在競爭的研究方向,且缺乏領導力決定哪個方向最具生產力。某些模型架構選擇未進行適當的消融測試,但被直接加入模型。這導致擴展梯度管理不善。
以OpenAI訓練GPT 4.5為例,說明擴展實驗的難度。OAI的內部代碼monorepo對訓練模型至關重要,因為他們需要一個已知未受污染的驗證數據集,以在訓練消融時測量困惑度。在擴展GPT 4.5訓練實驗時,他們看到模型泛化能力的可喜進展,但中途發現monorepo的部分內容直接從公開數據複製粘貼。模型並非泛化,而是在重現訓練數據集中記憶的代碼!大型預訓練運行需要極大的勤奮和準備才能有效執行。
儘管存在這些技術問題,並非一無所獲。Meta仍能將logits提煉到更小、更高效的預訓練模型Maverick和Scout,繞過了大型模型的一些錯誤架構選擇。提煉對小型模型比強化學習更高效。即便如此,這些模型仍受源模型的限制,無法在同等規模中名列前茅。
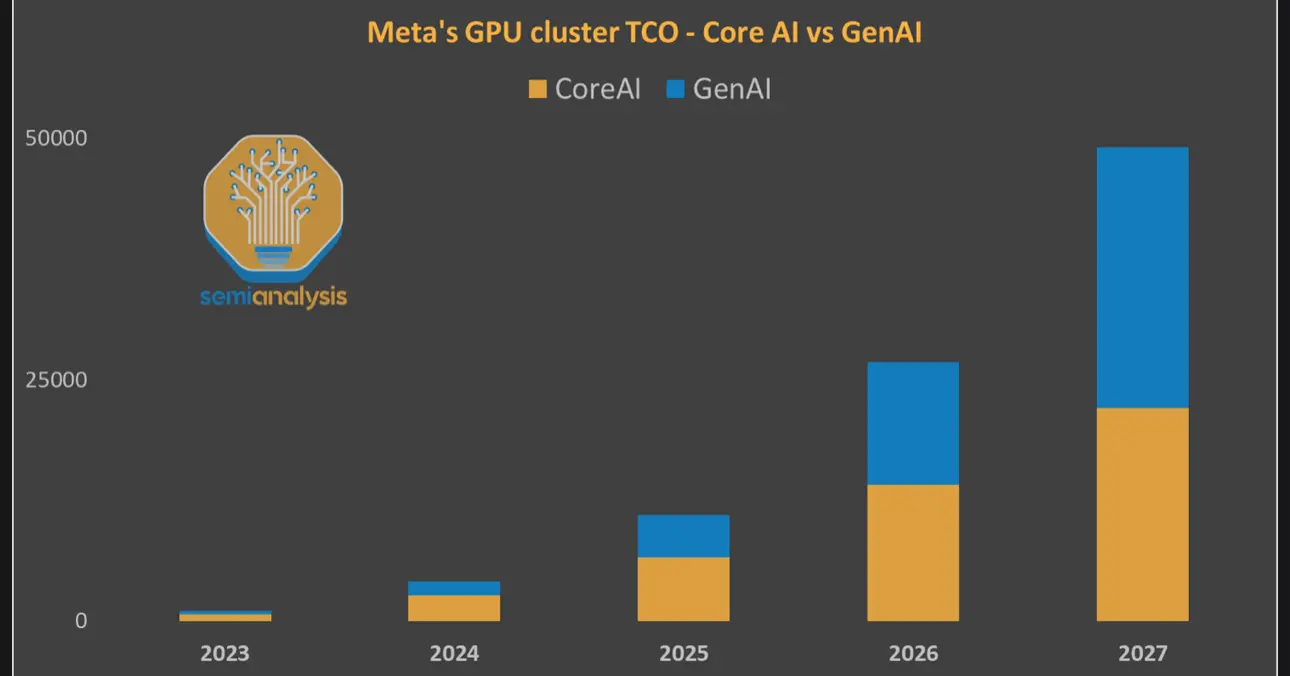
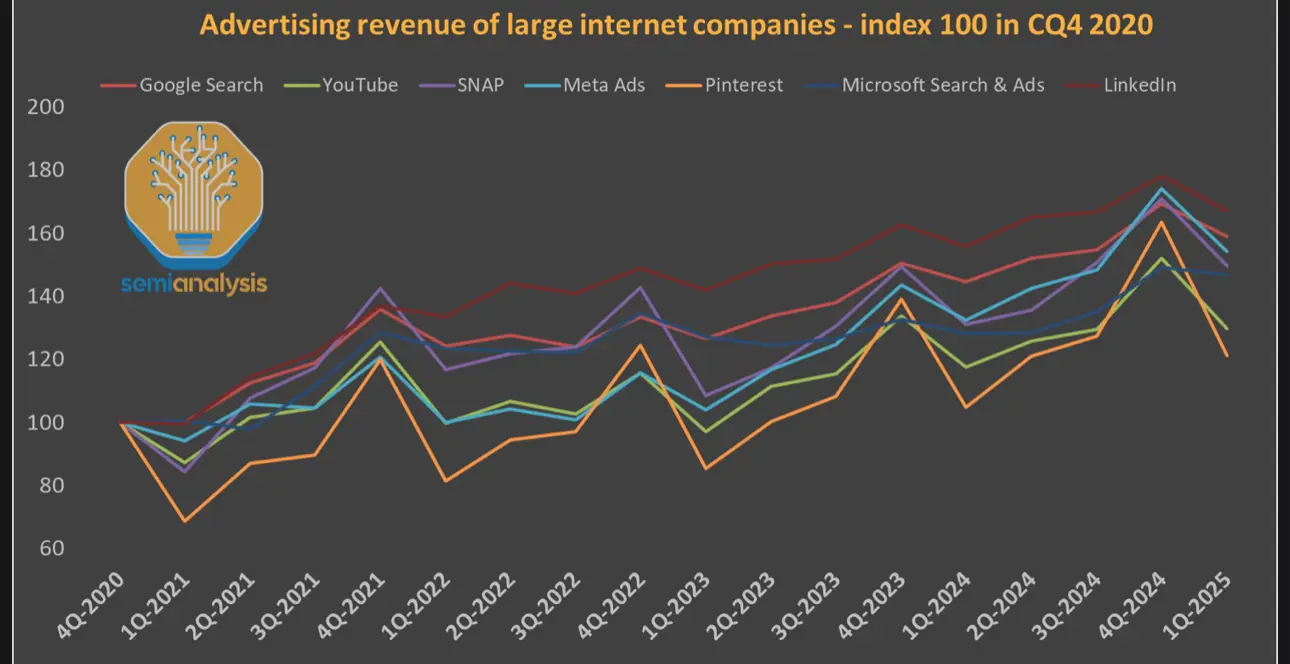

 仲係靠fb ig老本
仲係靠fb ig老本