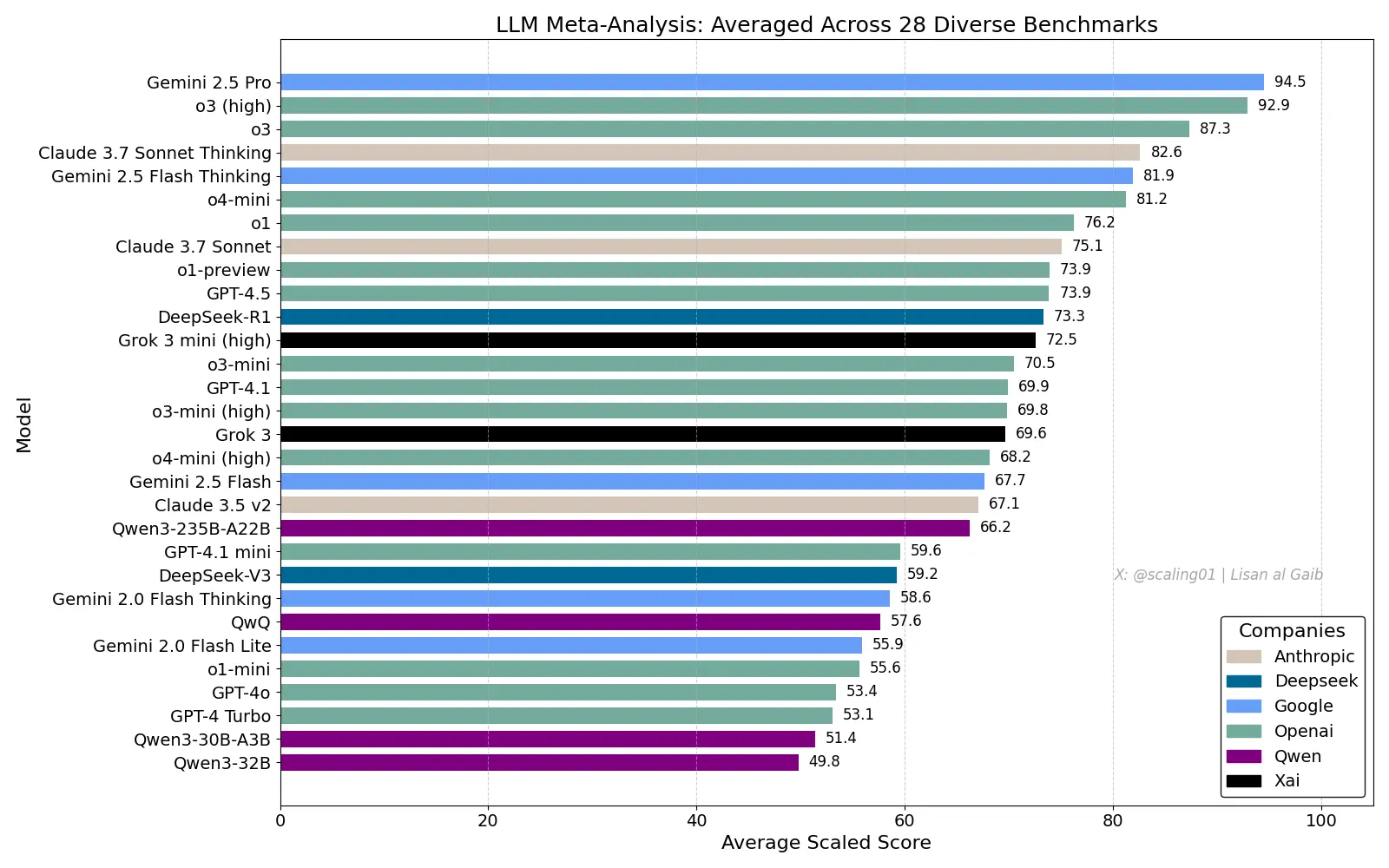
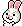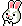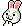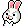LLM 排行表
sparda
9 回覆
0 Like
0 Dislike
sparda
2025-05-06 22:02:33
source:
https://x.com/scaling01/status/1919217718420508782
牙Cloud老公
2025-05-06 22:03:26
你老母排行表?
己攵口羊女子
2025-05-07 00:37:47
咁睇嘅話Qwen3其實做得幾好
基本上真係可以local行而有4o嘅性能
唔似係DeepShit R1話就話可以自己host但係671B
debugger;
2025-05-07 00:48:14
好難想像依家一個local 32b model已經勁過上年既gpt4
大棍巴
2025-05-07 09:40:54
o3/4-mini (medium/low) > o3/4-mini (high)?
sparda
2025-05-07 09:44:46
28種benchmark, 即係廣義應用
high似專業應用,所以可能唔夠泛用,有啲咪答得唔好
利申: 無睇嗰28種benchmark係乜, 鳩估
大棍巴
2025-05-07 09:52:36
High應該純粹係thinking token多左(OpenAI叫佢做Reasoning effort,個base model應該係一樣),所以先覺得奇
己攵口羊女子
2025-05-12 12:05:31
o3 mini 畀人屌話有hallucination rate高
可能High thinking token多啲導致佢更多幻覺,從而冇咁準
大棍巴
2025-05-12 12:25:04
OpenAI份technical report冇比較到o4-mini high同low之間嘅hallucination rate,只提到o4-mini作為細model會比較容易有。
但實際上o3都hallucinate得勁過o1,真正原因可能佢地自己先知/都唔知
第 1 頁
吹水台
自選台
熱 門
最 新
手機台
時事台
政事台
World
體育台
娛樂台
動漫台
Apps台
遊戲台
影視台
講故台
健康台
感情台
家庭台
潮流台
美容台
上班台
財經台
房屋台
飲食台
旅遊台
學術台
校園台
汽車台
音樂台
創意台
硬件台
電器台
攝影台
玩具台
寵物台
軟件台
活動台
電訊台
直播台
站務台
黑 洞