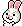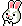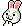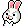昇騰晶片對SemiAnalysis來說並不陌生,但在系統比微架構更重要的世界中,華為正在推動人工智慧系統性能的極限。雖然存在取捨,但考慮到出口管制和國內良率不佳,中國出口管制顯然存在更多漏洞。
雖然昇騰晶片可在中芯國際製造,但我們注意到,這是一款全球化的晶片,採用韓國的HBM記憶體、台積電的主要晶圓生產,並由來自美國、荷蘭和日本的數百億美元晶圓製造設備製造。我們深入探討了中國國產生產的可能性、積極規避出口管制的行為,以及美國政府為何需要聚焦這些關鍵新領域以限制中國的人工智慧能力。
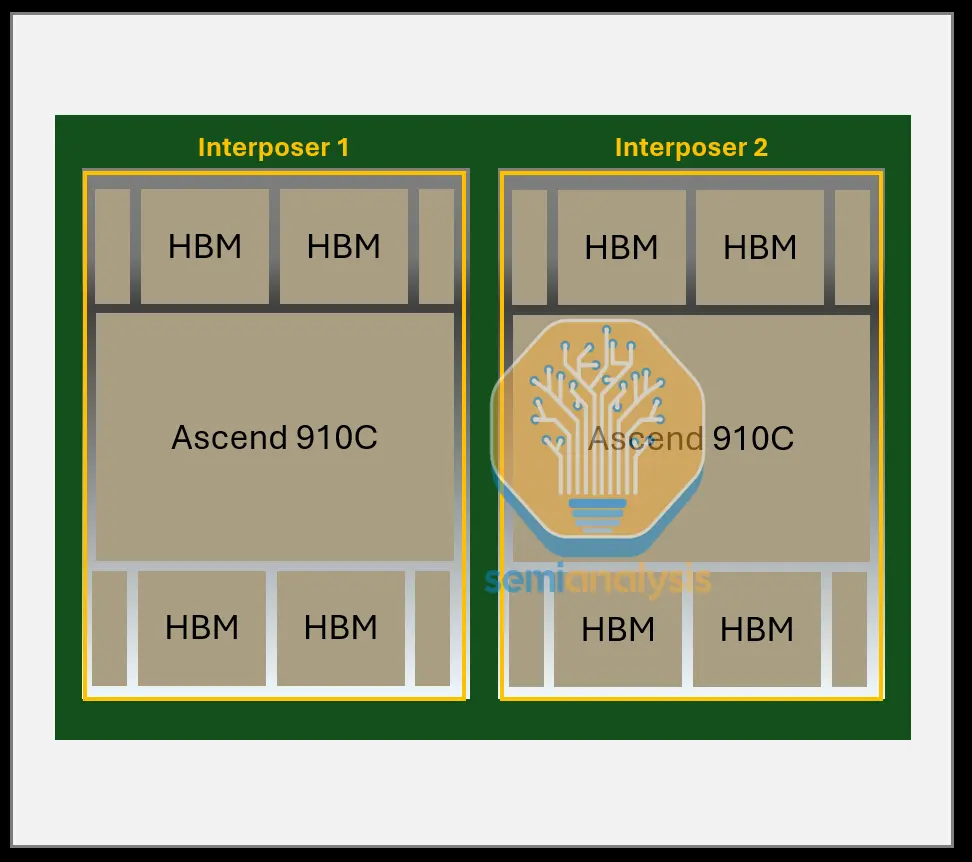
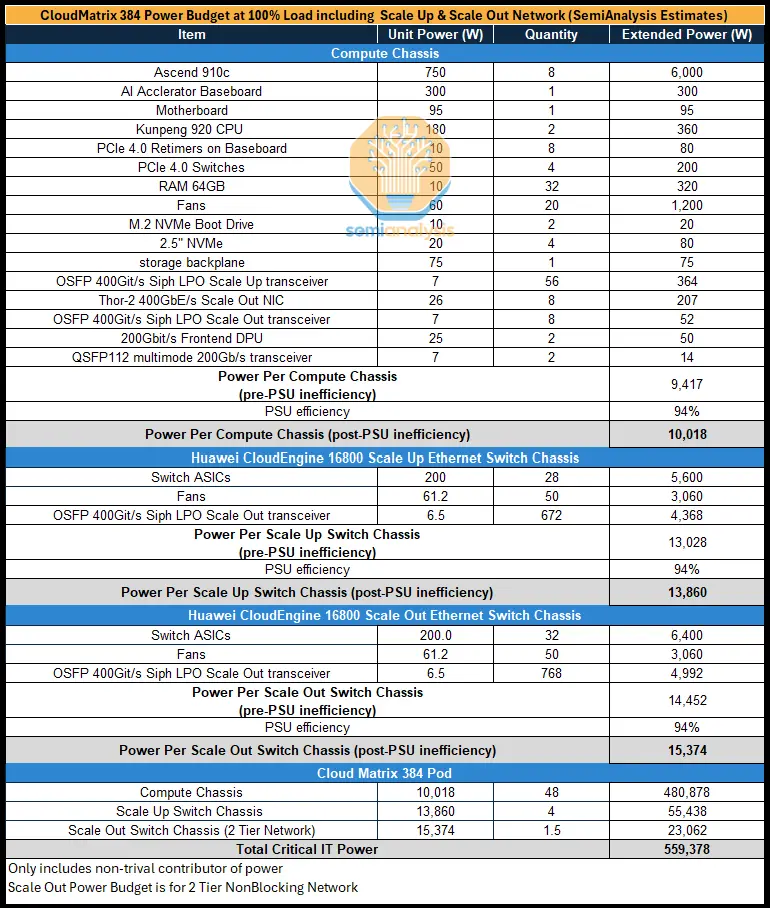
華為在晶片方面落後一代,但其規模擴展解決方案可說是領先Nvidia和AMD當前市場產品一代。那麼,華為CloudMatrix 384(CM384)的規格是什麼?CloudMatrix 384由384個昇騰910C晶片組成,通過全對全拓撲結構連接。取捨很簡單:擁有五倍於Nvidia Blackwell的昇騰晶片數量,足以抵銷每個GPU僅為Nvidia Blackwell三分之一性能的差距。
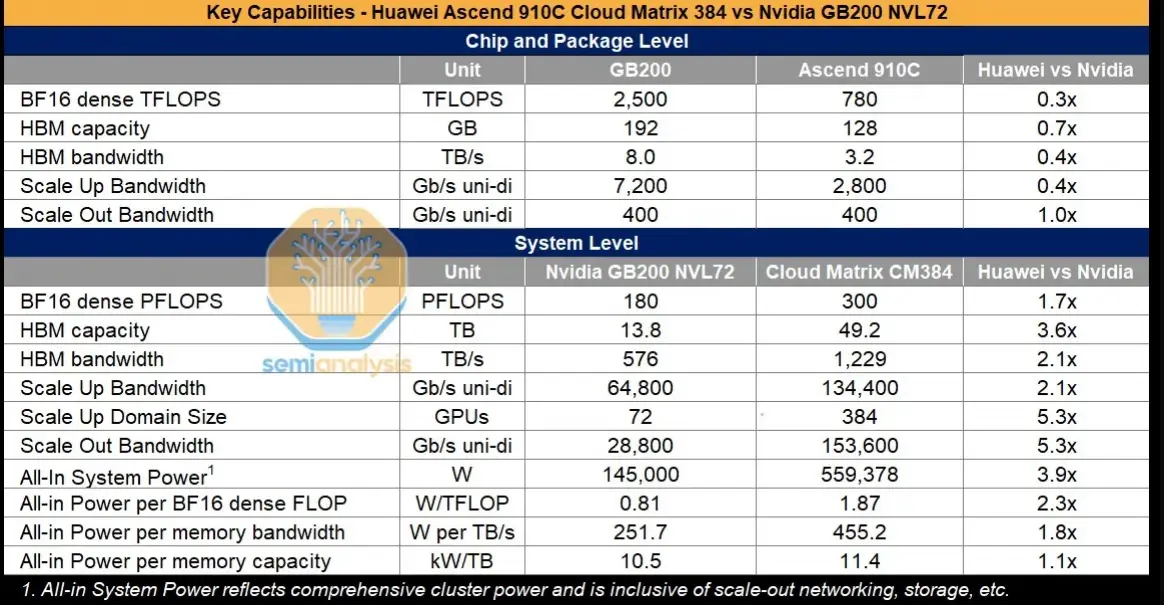
完整的CloudMatrix系統現在可提供300 PFLOPs的密集BF16運算能力,幾乎是GB200 NVL72的兩倍。憑藉超過3.6倍的總記憶體容量和2.1倍的記憶體頻寬,華為和中國現在擁有超越Nvidia的人工智慧系統能力。更重要的是,CM384特別適合中國的優勢,包括國內網路生產、防止網路故障的基礎設施軟體,以及隨著良率進一步提升,能夠擴展到更大規模的能力。
然而,缺點在於其功耗是GB200 NVL72的3.9倍,每FLOP功耗效率差2.3倍,每TB/s記憶體頻寬功耗效率差1.8倍,每TB HBM記憶體容量功耗效率差1.1倍。功耗方面的不足雖然相關,但在中國並非限制因素。
中國沒有電力限制,只有矽的限制
西方常說人工智慧受電力限制,但在中國情況恰恰相反。過去十年,西方已將主要依賴煤炭的電力基礎設施轉向更綠色的天然氣和可再生能源發電,並提高人均能源使用效率。而中國則相反,隨著生活水平提升和持續的大量投資,電力需求大幅增長。
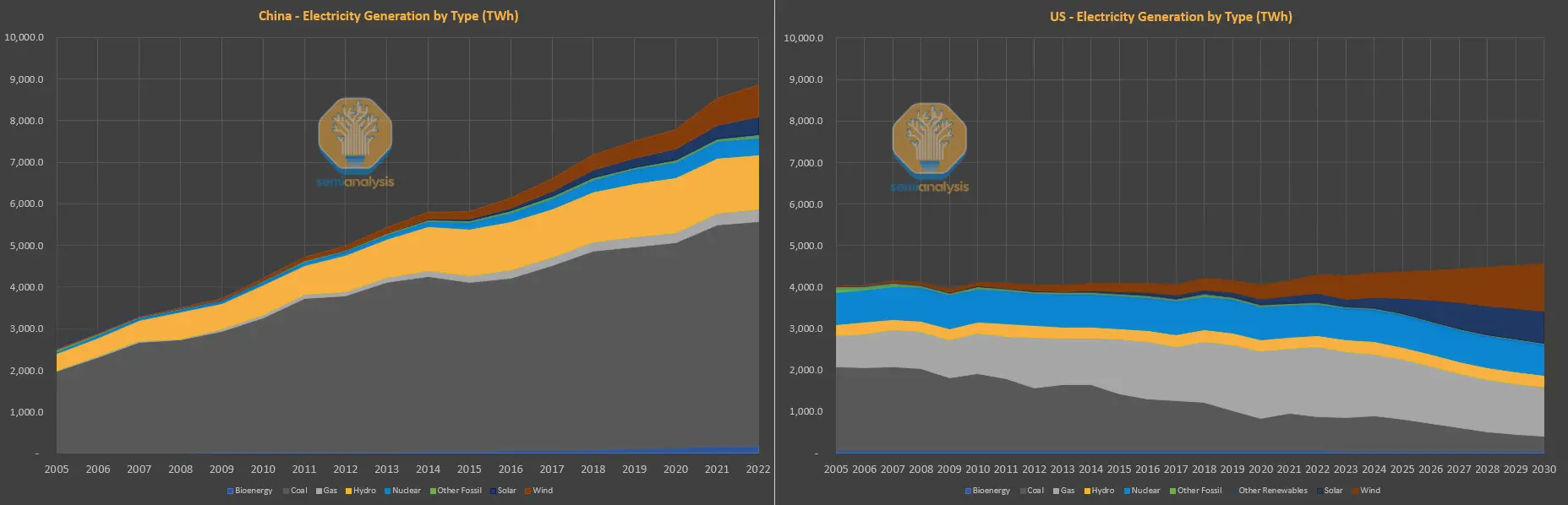
中國的電力主要由煤炭驅動,但中國也擁有最大的太陽能、水力、風力發電裝機容量,並且現在是部署核能的領先者。美國僅維持1970年代部署的核能發電能力。簡單來說,升級和增加美國電網容量已是一項喪失的能力,而中國自2011年以來,約過去十年,已新增相當於整個美國電網的容量。
如果因相對充足的電力而沒有電力限制,放棄功耗密度並增加規模擴展(包括設計中的光學元件)是合理的。CM384的設計考慮了機架外的系統級限制,我們認為,不僅僅是相對的電力可用性限制了中國的人工智慧雄心。我們認為,華為的解決方案有多種方式可以繼續擴展。
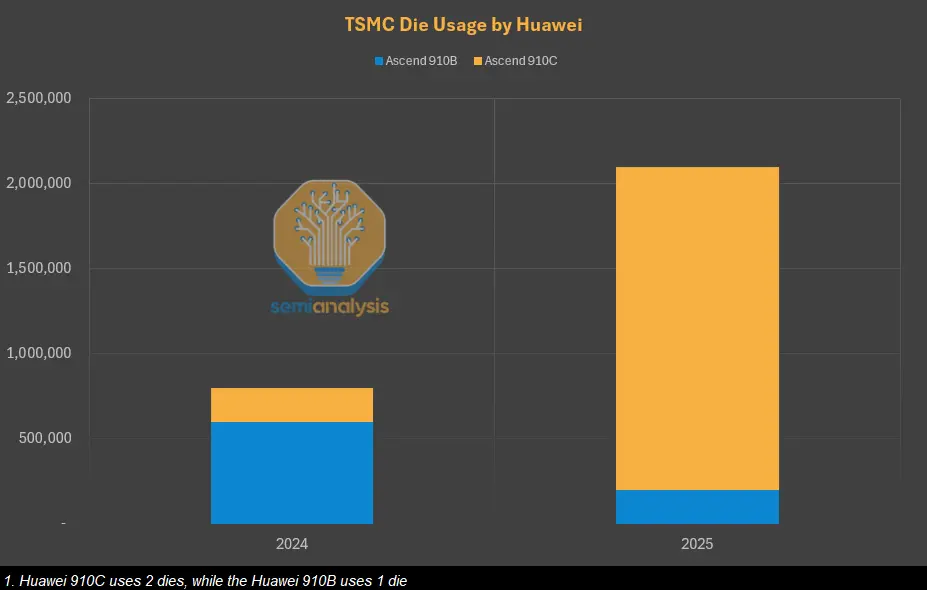
中國能製造多少昇騰910C和CloudMatrix 384? 一個常見的誤解是華為的910C是在中國製造的。它完全在中國設計,但中國仍高度依賴外國生產。無論是三星的HBM、台積電的晶圓,還是來自美國、荷蘭和日本的設備,中國對外國產業的依賴很大。
雖然中芯國際(中國最大的晶圓代工廠)具備7奈米製程能力,但昇騰910B和910C絕大多數是由台積電的7奈米製程生產。事實上,美國政府、TechInsights等人已取得昇騰910B和910C進行分析,每一顆晶片都使用台積電的晶粒。華為通過另一家公司Sophgo購買了約5億美元的7奈米晶圓,成功繞過對其的台積電制裁。
台積電因公然違反制裁被罰款10億美元,僅為其獲利的兩倍。有傳言稱華為繼續通過另一家第三方公司從台積電獲得晶圓,但我們無法證實此傳言。
華為的HBM取得
領先技術對外國的依賴是問題的一部分,但中國對HBM(高頻寬記憶體)的依賴更大。中國目前無法可靠製造HBM,長鑫存儲(CXMT)距離量產合理規模仍需一年。幸運的是,三星挺身而出,成為中國HBM的最大供應商,華為因此得以囤積總計1300萬個HBM堆疊,可用於160萬個昇騰910C封裝,這是在任何HBM禁令實施之前。
此外,被禁的HBM仍在通過轉口貿易進入中國。HBM出口禁令僅針對原始HBM封裝。搭載HBM的晶片只要不超過FLOPS規定,仍可出口。CoAsia Electronics是大中華區三星HBM的獨家經銷商,他們一直在向ASIC設計服務公司Faraday出貨HBM2E,後者委託日月光(SPIL)將其與廉價的16奈米邏輯晶粒“封裝”在一起。
Faraday隨後將此系統級封裝出貨至中國,這在技術上是允許的,但中國公司可通過拆焊回收HBM。我們認為他們採用了技術手段,使HBM易於從封裝中提取,例如使用非常弱的低溫焊錫凸點,因此當我們說“封裝”時,是以最寬鬆的方式來描述。
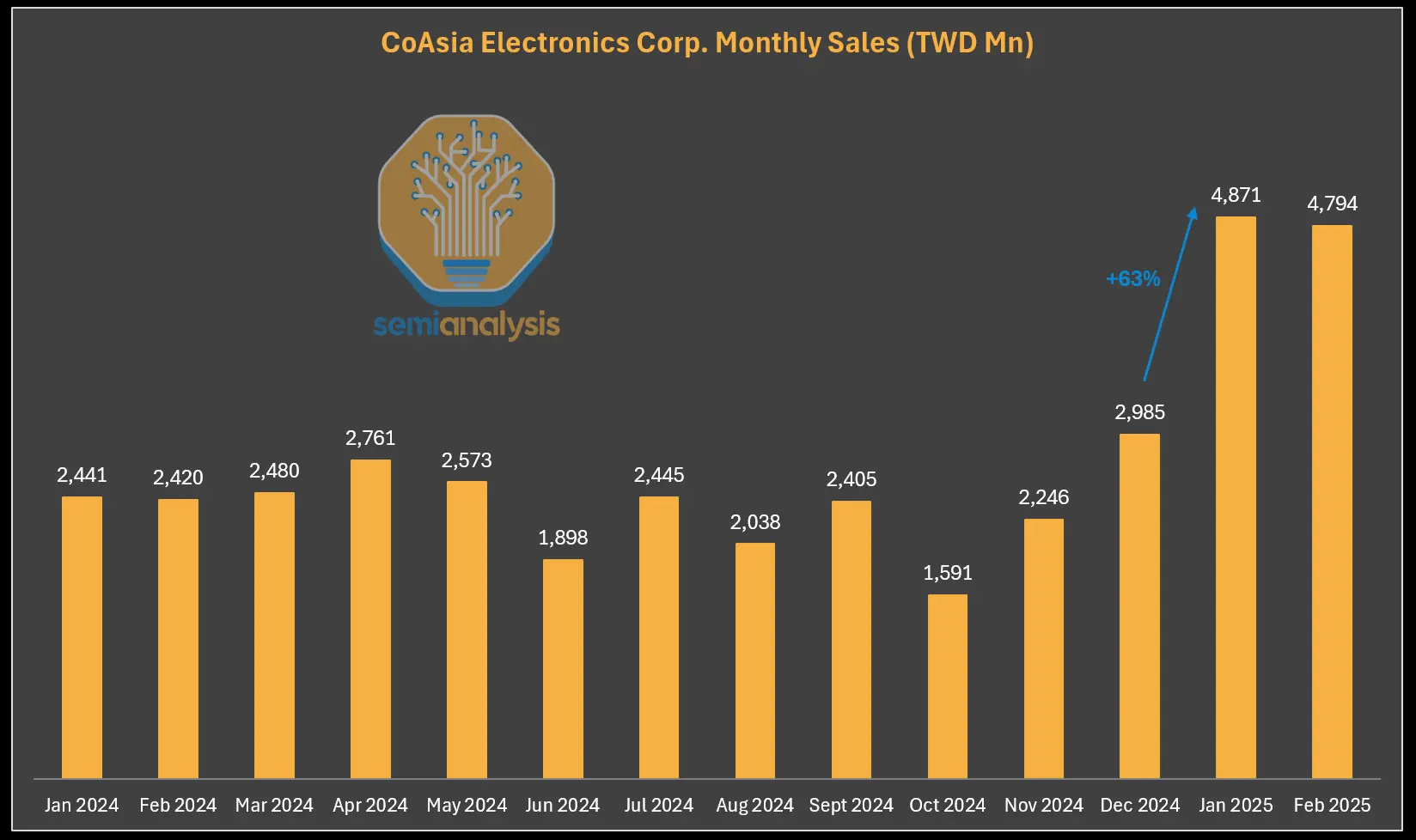
CoAsia的收入自2025年出口管制生效後爆炸性增長,並非巧合。
中國國內晶圓代工廠仍可擴大產能
雖然仍需依賴外國生產,但中國國內半導體供應鏈能力已迅速提升,且仍被低估。我們一直對中芯國際(SMIC)和長鑫存儲(CXMT)的製造能力敲響警鐘。良率和產量仍是問題,但長期來看,中國GPU生產擴大的情況值得關注。
中芯國際和長鑫存儲已接收價值數百億美元的設備,並且儘管受到制裁,仍從外國獲得大量獨家供應的化學品和材料。
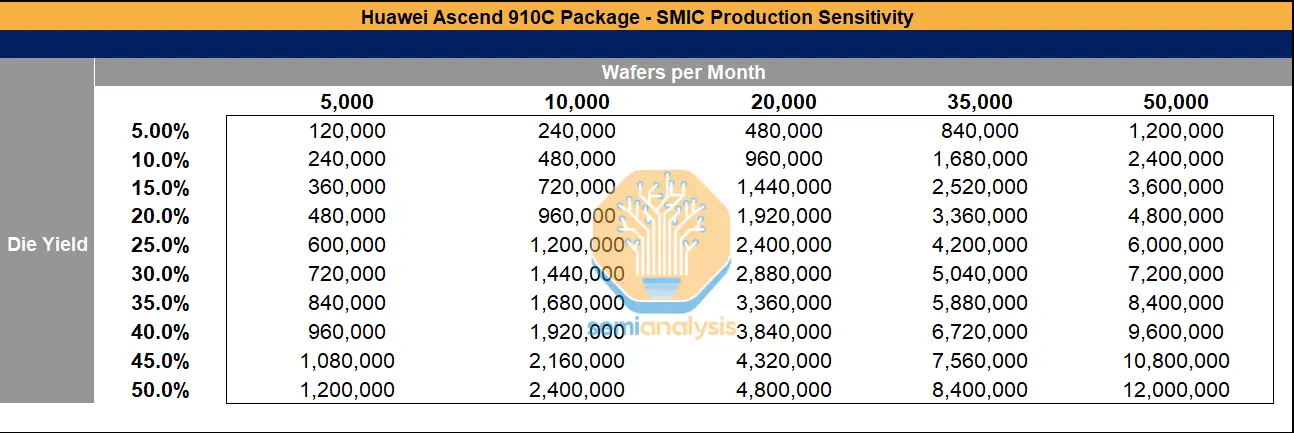
中芯國際正在上海、深圳和北京擴建先進節點產能。今年其月產能將接近5萬片晶圓,且由於持續取得外國設備以及制裁和執法效果不足,產能仍在擴張。如果良率提升,中芯國際在華為昇騰910C封裝上的產量可能達到可觀數字。
雖然台積電在2024年和2025年提供了290萬顆晶粒,足以支持80萬個昇騰910B和105萬個昇騰910C,但如果HBM、晶圓製造設備、設備維修和光刻膠等化學品未受到有效控制,中芯國際的生產潛力可能大幅提升產能。