「另一方面,人類醫生單獨的診斷表現較低」,並補充道,「然而,當人類醫生與人工智能合作時,根據使用方式的不同,表現差距很大。」
AI報告涉及GPT-4和美國的50名臨床醫生(26名專家和24名住院醫生),為他們提供了六個難以診斷的患者病例。
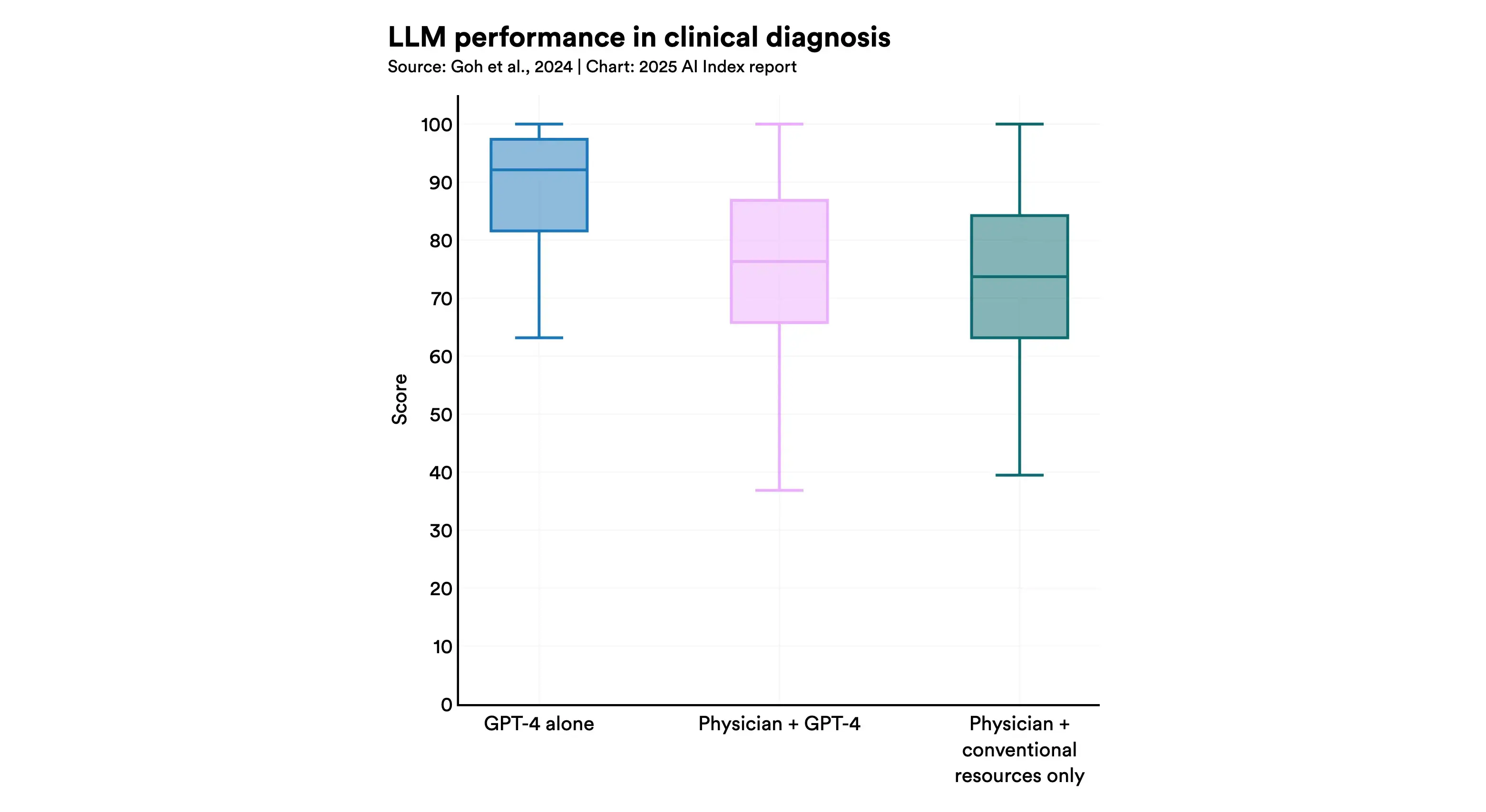
接下來,比較了「單獨使用 GPT- 4」、「人類醫生與 GPT-4 合作」和「單獨使用人類醫生」的診斷效能。
第一個實驗分為「GPT -4 對抗人類醫生」,第二個實驗分為「GPT- 4 和人類醫生合作對抗人類醫生」,考察診斷的準確性。
結果,GPT- 4診斷組的準確率中位數(92%)比僅由人類醫生診斷的組別準確率(76%)高出 16 個百分點。
此外,與GPT- 4 合作的醫生組的得分中位數(76%)僅比僅由人類醫生診斷的組別(74%)高出 2 個百分點。
報告評估稱,「本次實驗結果表明,總體而言,GPT-4 診斷的性能最高、最一致」,且「即使AI與醫生協作,其性能也會因醫生個體的判斷方法或運用能力而有所不同,導致準確度下降和不一致」。
隨著被認為是全球最權威的人工智慧白皮書《AI Index》發布分析結果,顯示GPT-4等生成式人工智慧模型的診斷能力優於醫生,加上Apple AI醫生預計明年亮相,相信AI醫生真正走進醫院的日子已經不遠了。
「最近的研究表明,人工智慧在癌症檢測和危重病人識別等領域的表現優於醫療專業人員」,「人工智慧的應用範圍正在從簡單的診斷擴展到更複雜的臨床判斷領域。」
此外,在衡量 GPT- 4臨床知識表現的代表性標準「Med QA」基準測試中,截至去年,GPT- 4 的準確率為 96.0%。這一數字與 2022 年的 67.6% 相比,增加了 28.4 個百分點。 MedQA是基於美國國家醫師執照考試水平的醫學問題的測試,用於評估AI的臨床知識水平。
https://hai.stanford.edu/ai-index/2025-ai-index-report/science-and-medicine