在MiniMax-01系列模型中,我們做了大膽創新:首次大規模實現線性注意力機制,傳統Transformer架構不再是唯一的選擇。這個模型的參數量高達4560億,其中單次啟動459億。模型綜合性能比肩海外頂尖模型,同時能夠高效處理全球最長400萬token的上下文,是GPT-4o的32倍,Claude-3.5-Sonnet的20倍。
超長上下文、開啟Agent時代
我們相信2025年會是Agent高速發展的一年,不管是單Agent的系統需要持續的記憶,或是多Agent的系統中Agent之間大量的相互通信,都需要越來越長的上下文。在這個模型中,我們走出了第一步,並希望使用這個架構來持續建立複雜Agent所需的基礎能力。
極致性價比、不斷創新
受益於架構的創新、效率的優化、集群訓推一體的設計以及我們內部大量並發算力復用,我們得以用業內最低的價格區間提供文本和多模態理解的API,標準定價是輸入Token 人民幣1元/百萬Token,輸出Token 8元/百萬Token。歡迎大家在MiniMax 開放平台體驗、使用。
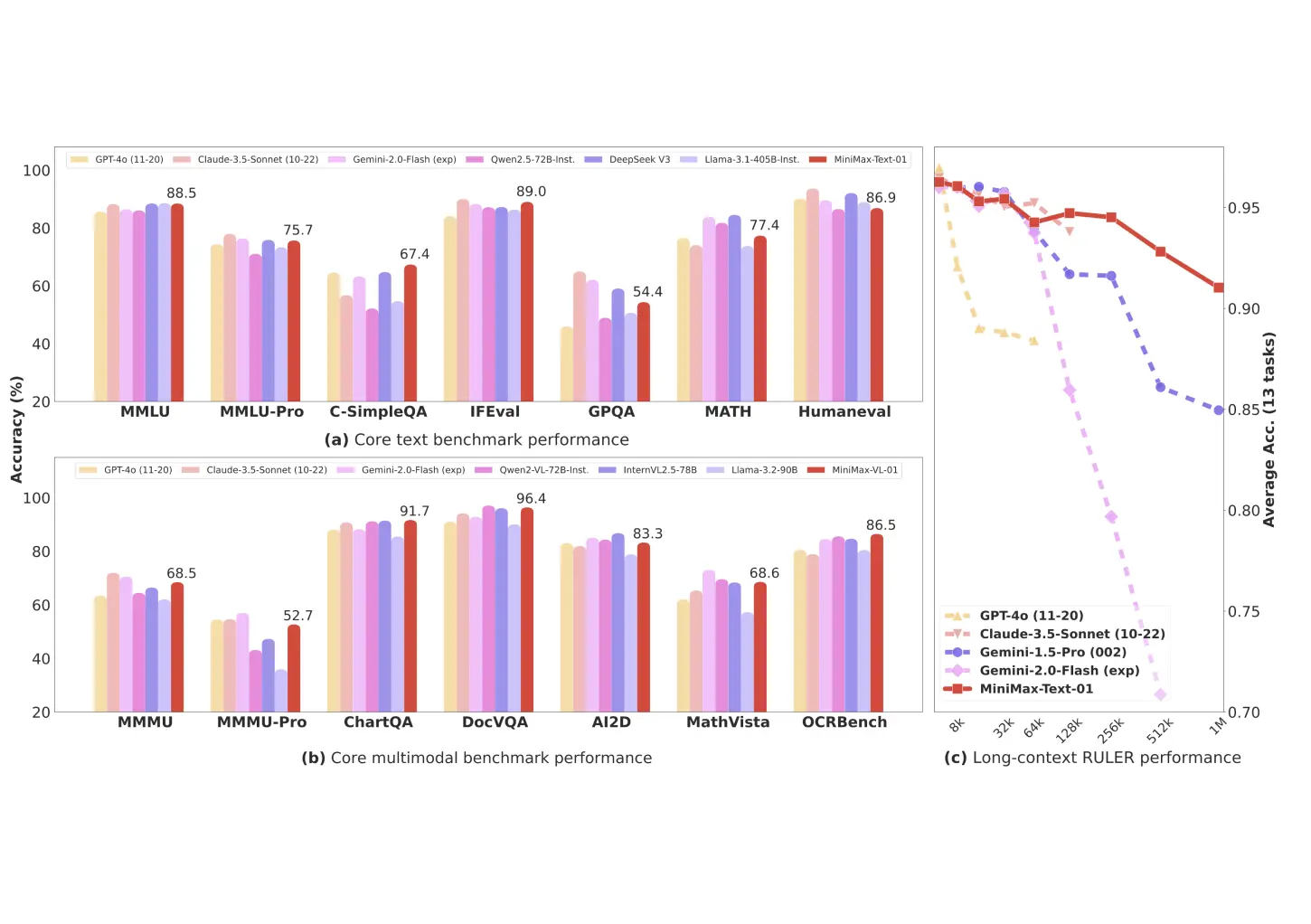
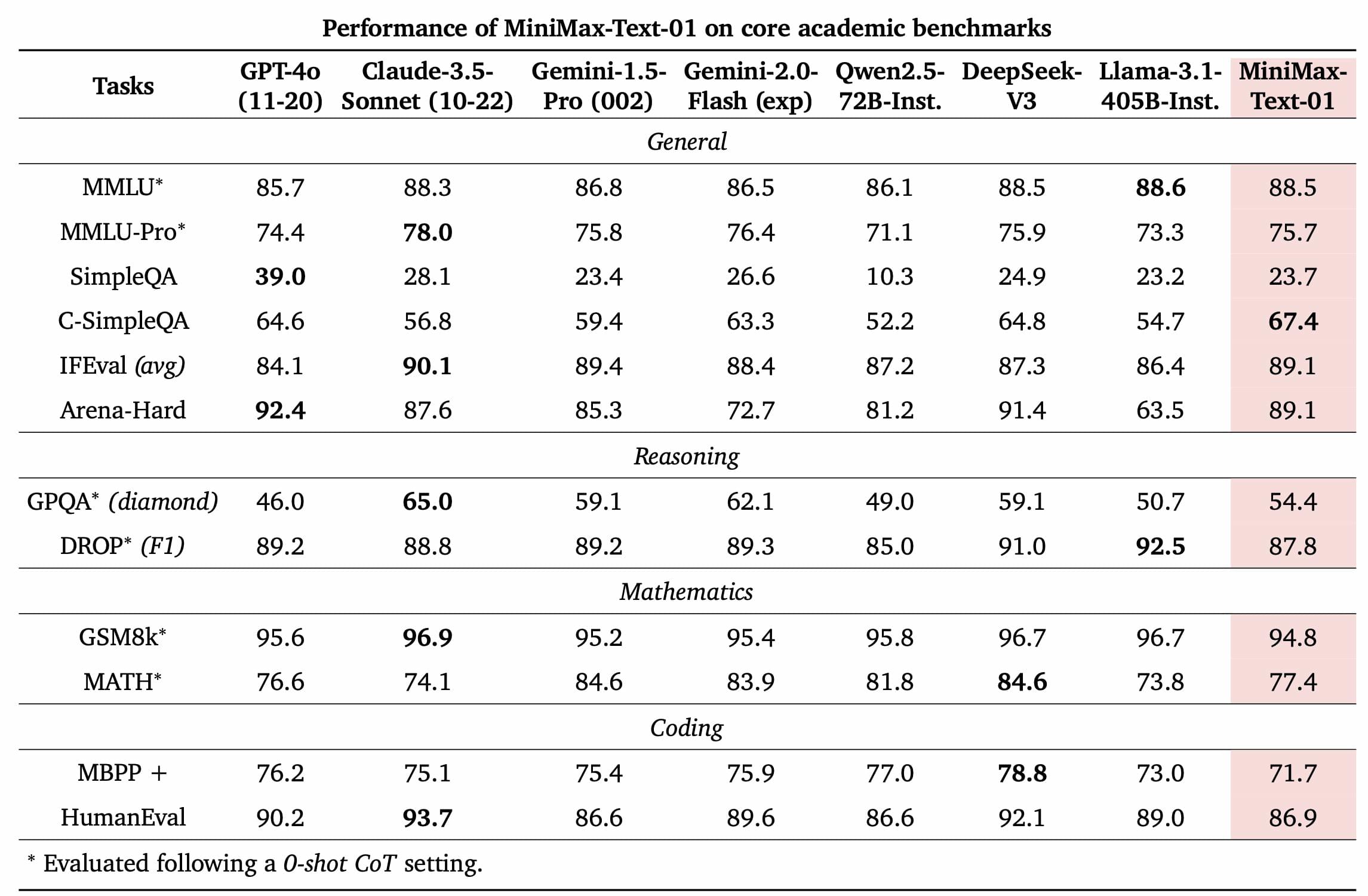
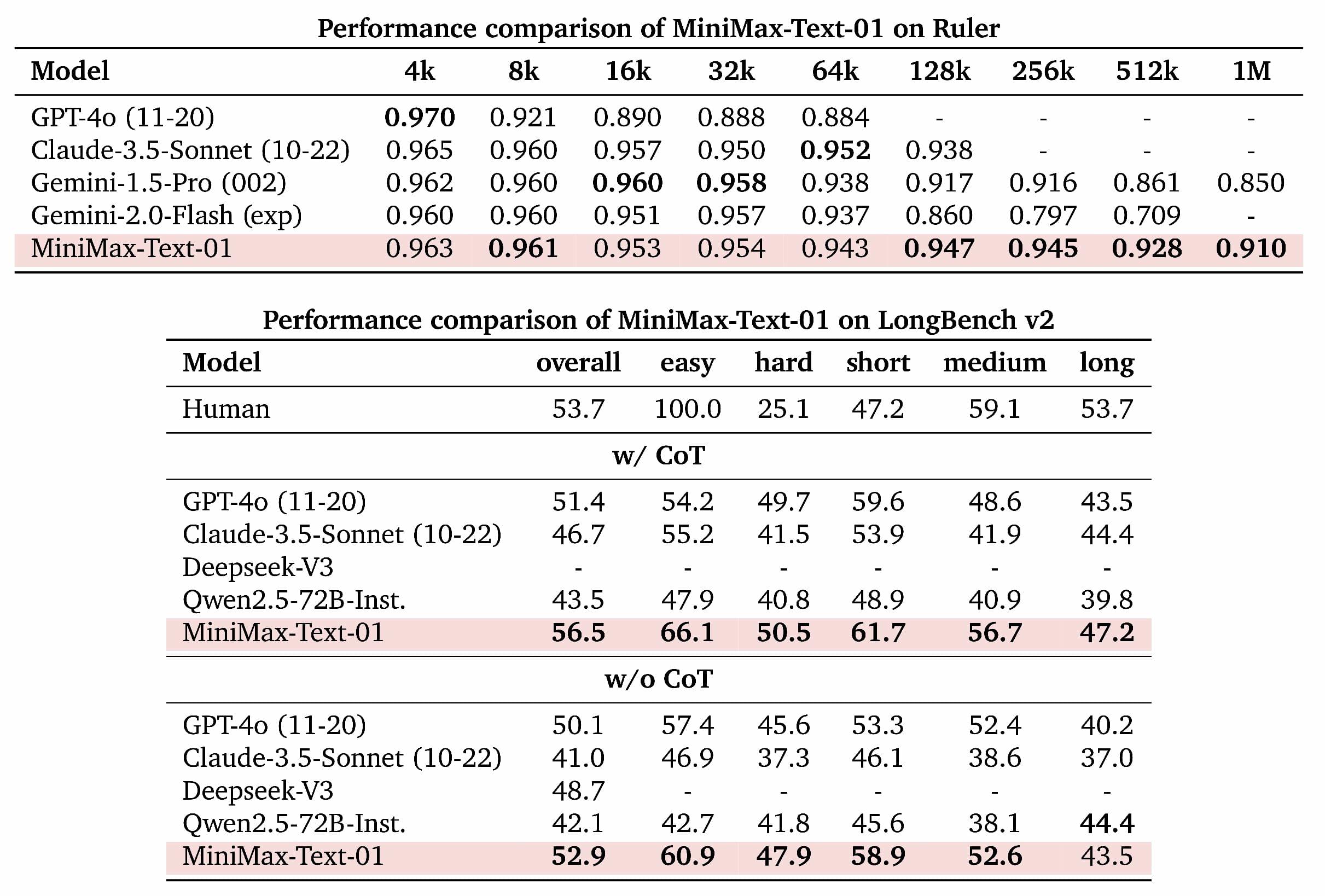
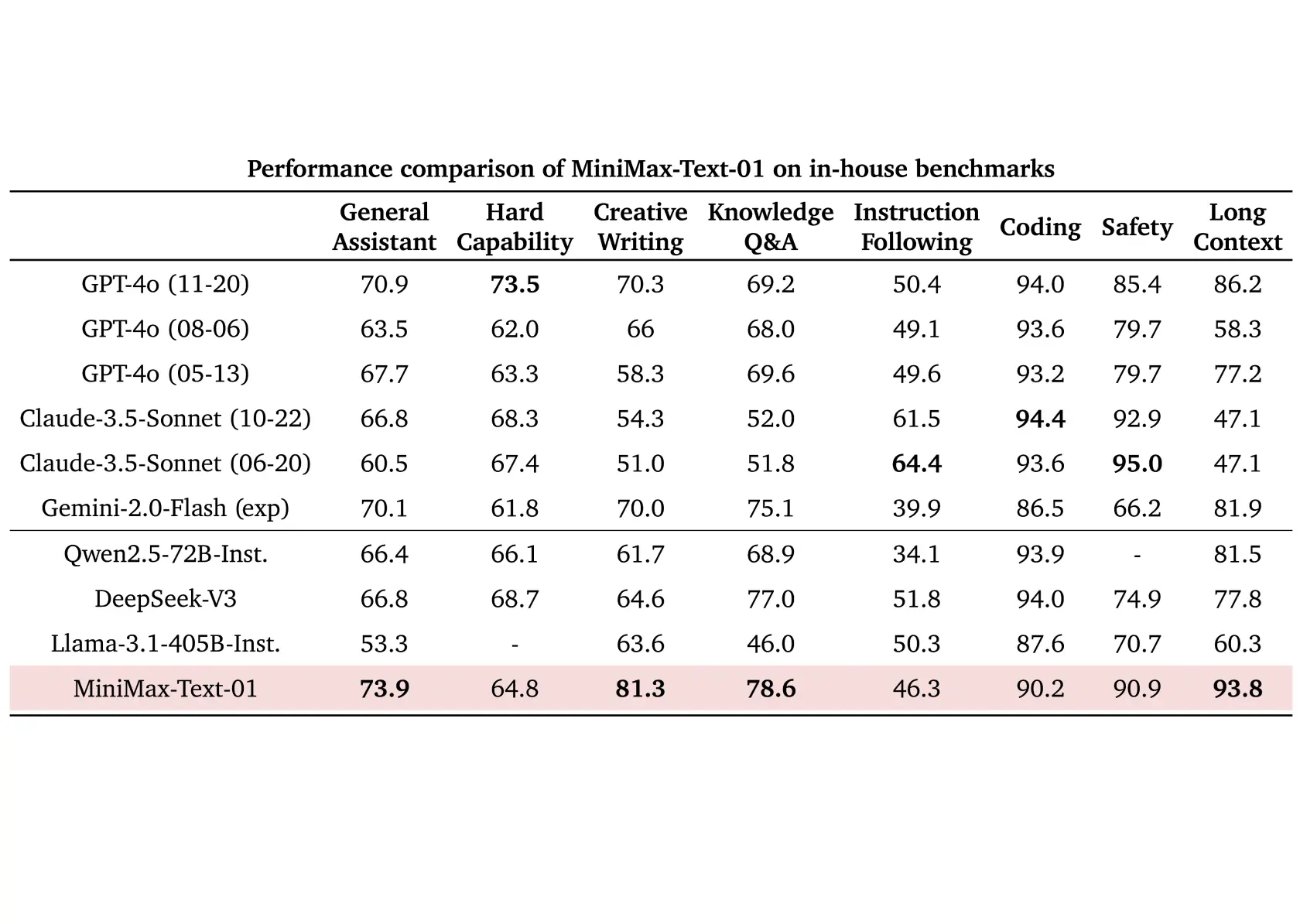
基於業界主流的文本和多模態理解評估結果如下圖所示,我們在大多數任務上追平了海外公認最先進的兩個模型,GPT-4o-1120以及Claude-3.5-Sonnet-1022。在長文任務上,我們比較了之前長文最好的模型Google的Gemini。如圖(c)所示,隨著輸入長度變長,MiniMax-Text-01 是效能衰減最慢的模型,顯著優於Google Gemini。
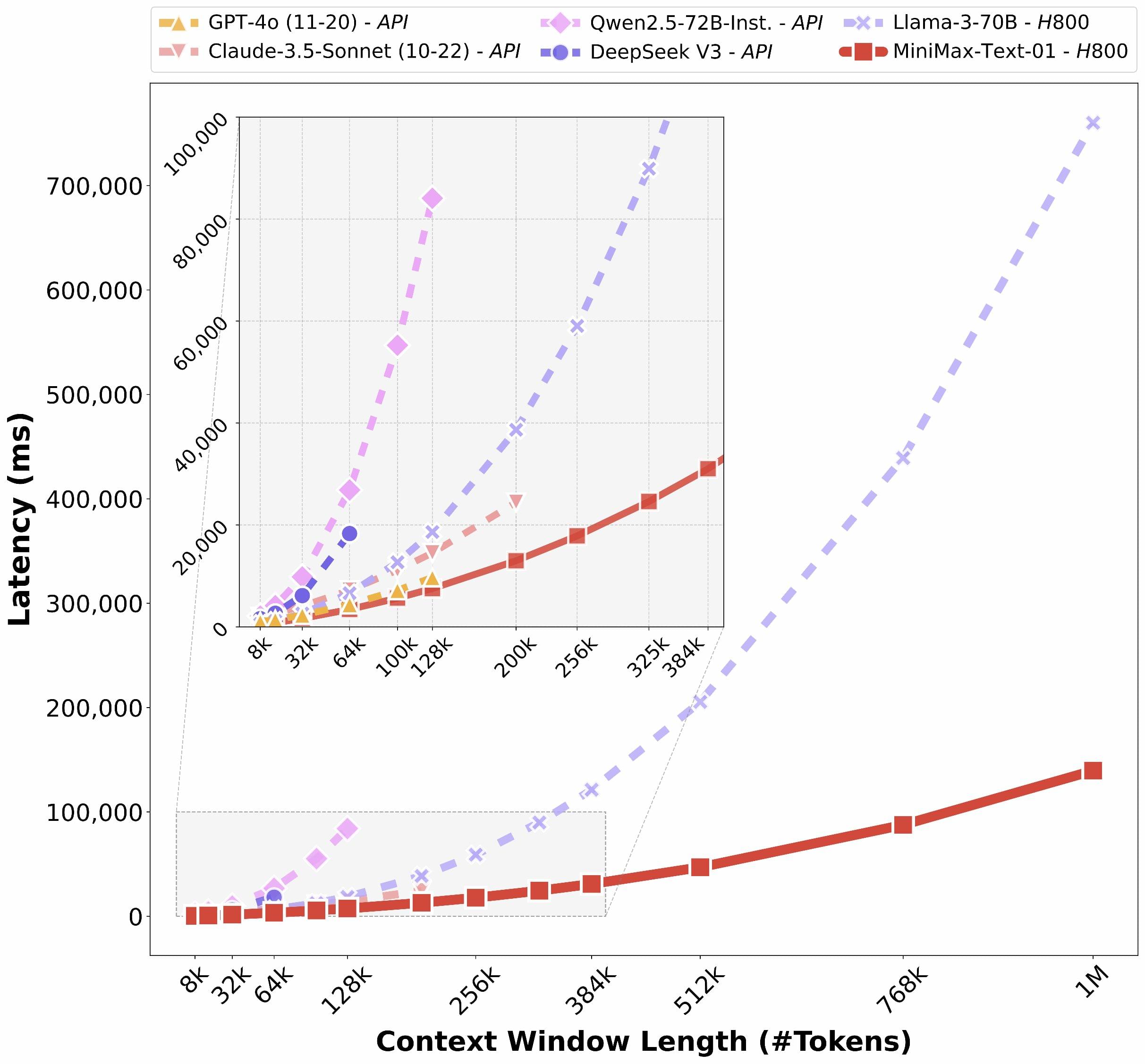
受惠於我們的架構創新,我們的模型在處理長輸入的時候有非常高的效率,接近線性複雜度。和其他全球頂尖模型的對比如下:
我們使用的結構如下,其中每8層中有7個是基於Lightning Attention的線性注意力,有一層是傳統的SoftMax注意力。
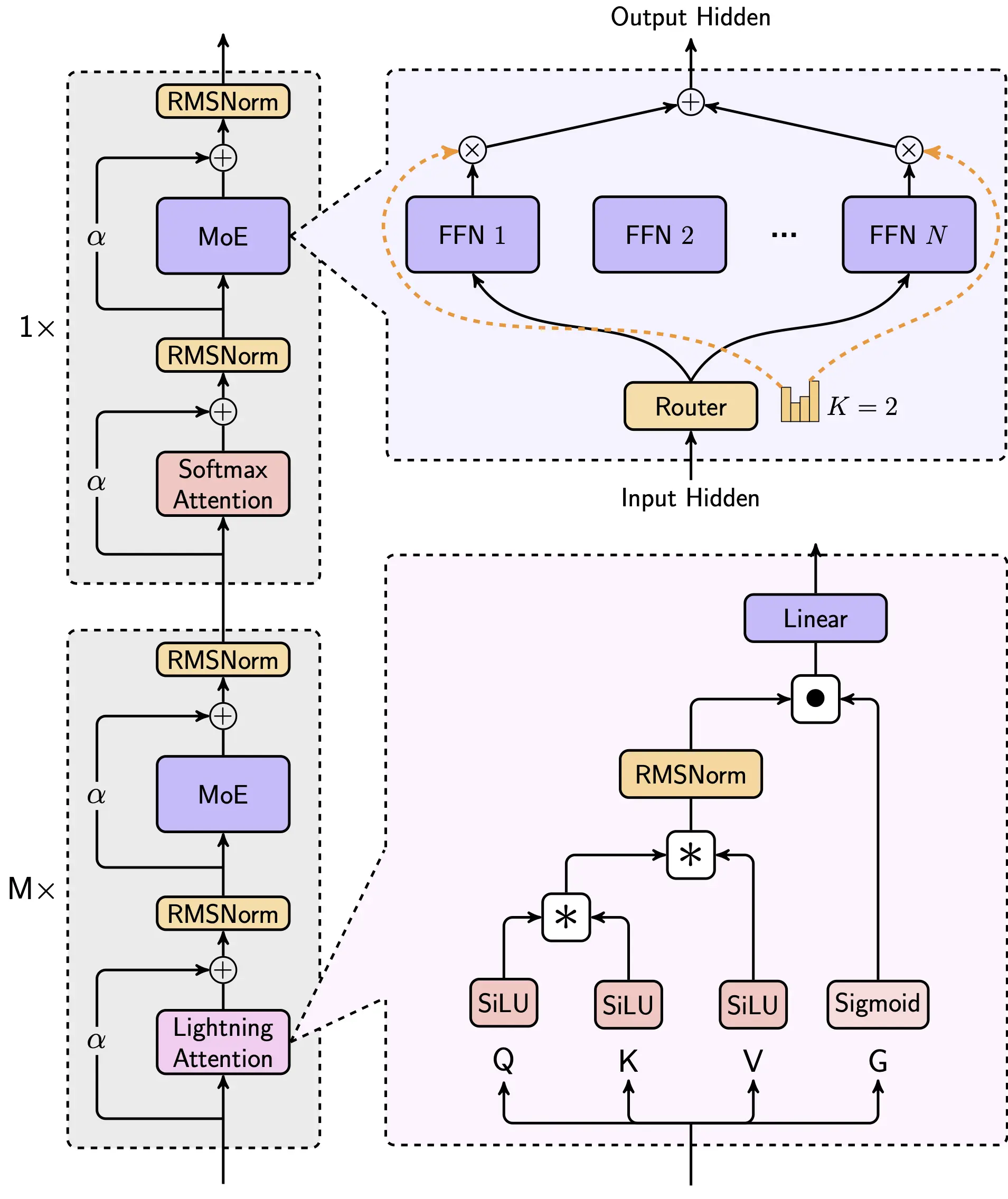
這是業界第一次把線性注意力機制擴展到商用模型的級別,我們從Scaling Law、與MoE的結合、結構設計、訓練優化和推理優化等層面做了綜合的考慮。由於是業界第一次做如此大規模的以線性注意力為核心的模型,我們幾乎重構了訓練和推理系統,包括更有效率的MoE All-to-all通訊優化、更長的序列的優化,以及推理層面線性注意力的高效Kernel實現。

 有啲唔同
有啲唔同