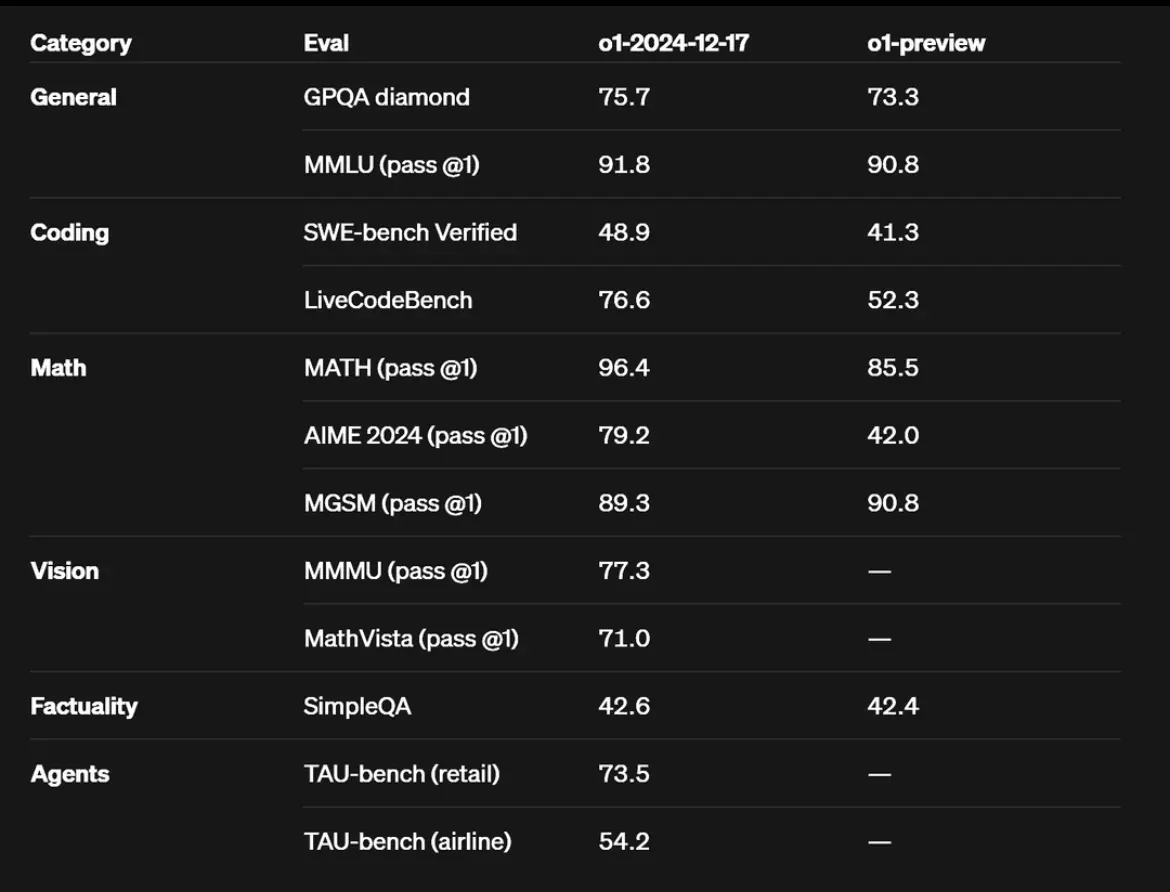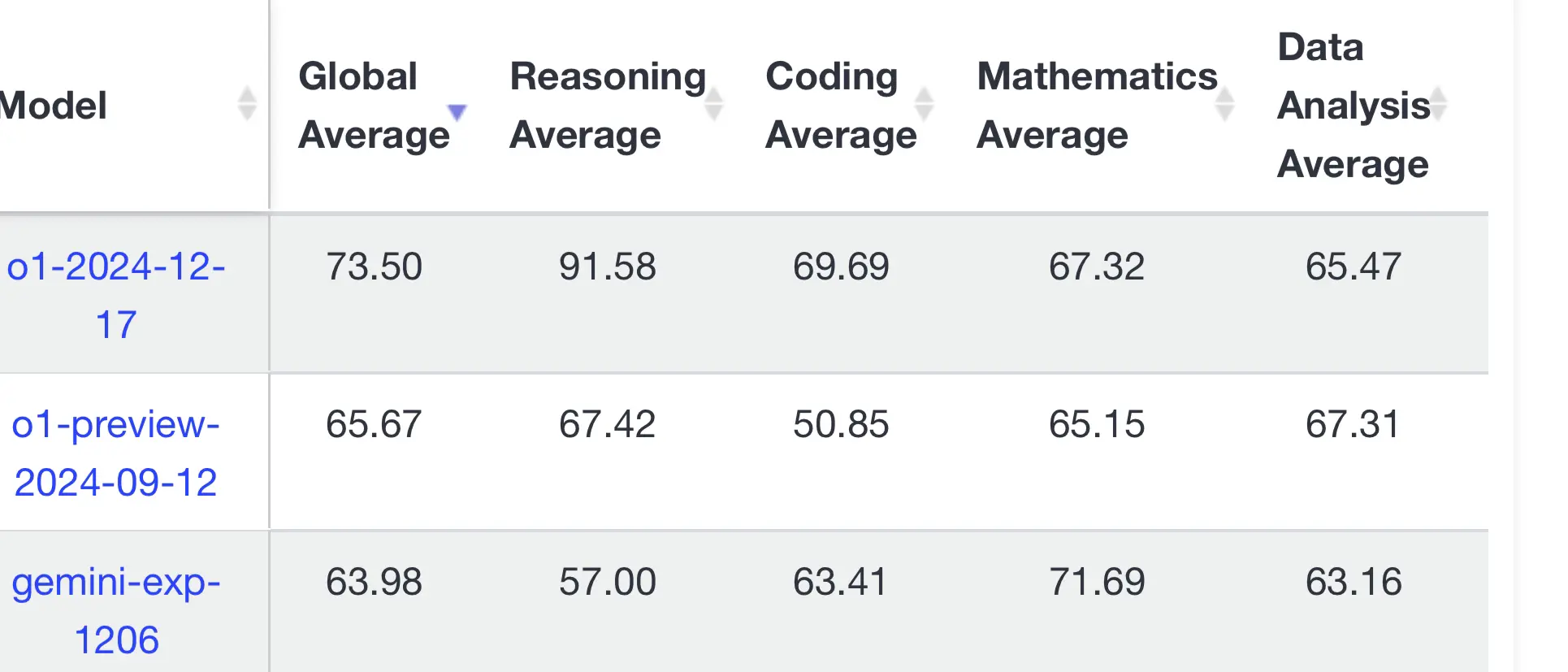
呢個係一個比較多人睇嘅benchmark
o1 最近先有api
o1 pro 未有api 應該 所以未有
reasoning 嗰part 91+
高過其他model 好多
但係translate 唔到去math同埋coding (尤其math)
coding 同math 相對underwhelming
以咁嘅成本嚟講 coding 淨係高sonnet +2.5
數仲差過gemini 1206 -4.3
可能證明llm 都係outside training data 冇乜用 冇乜generalize 嘅能力
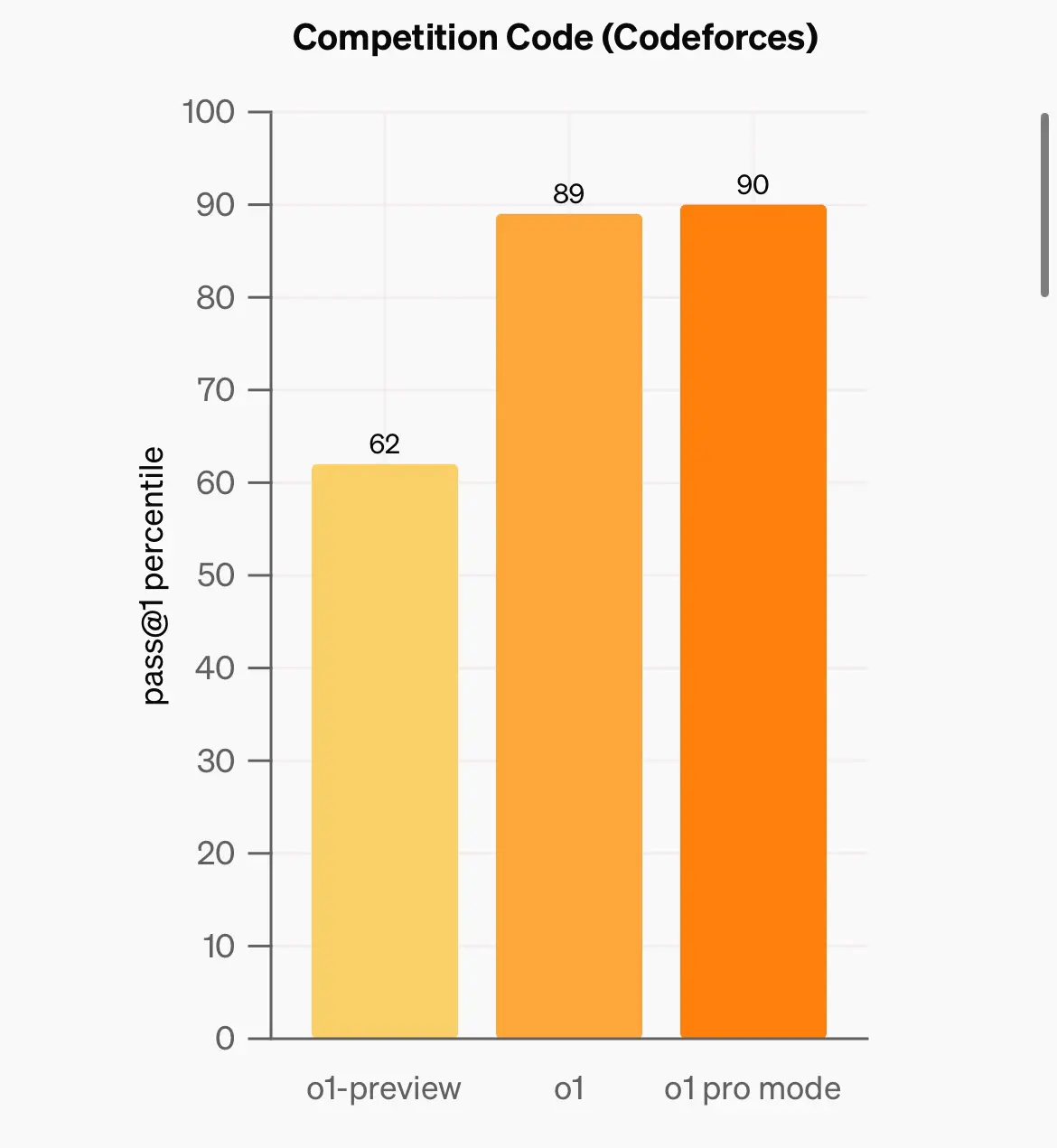
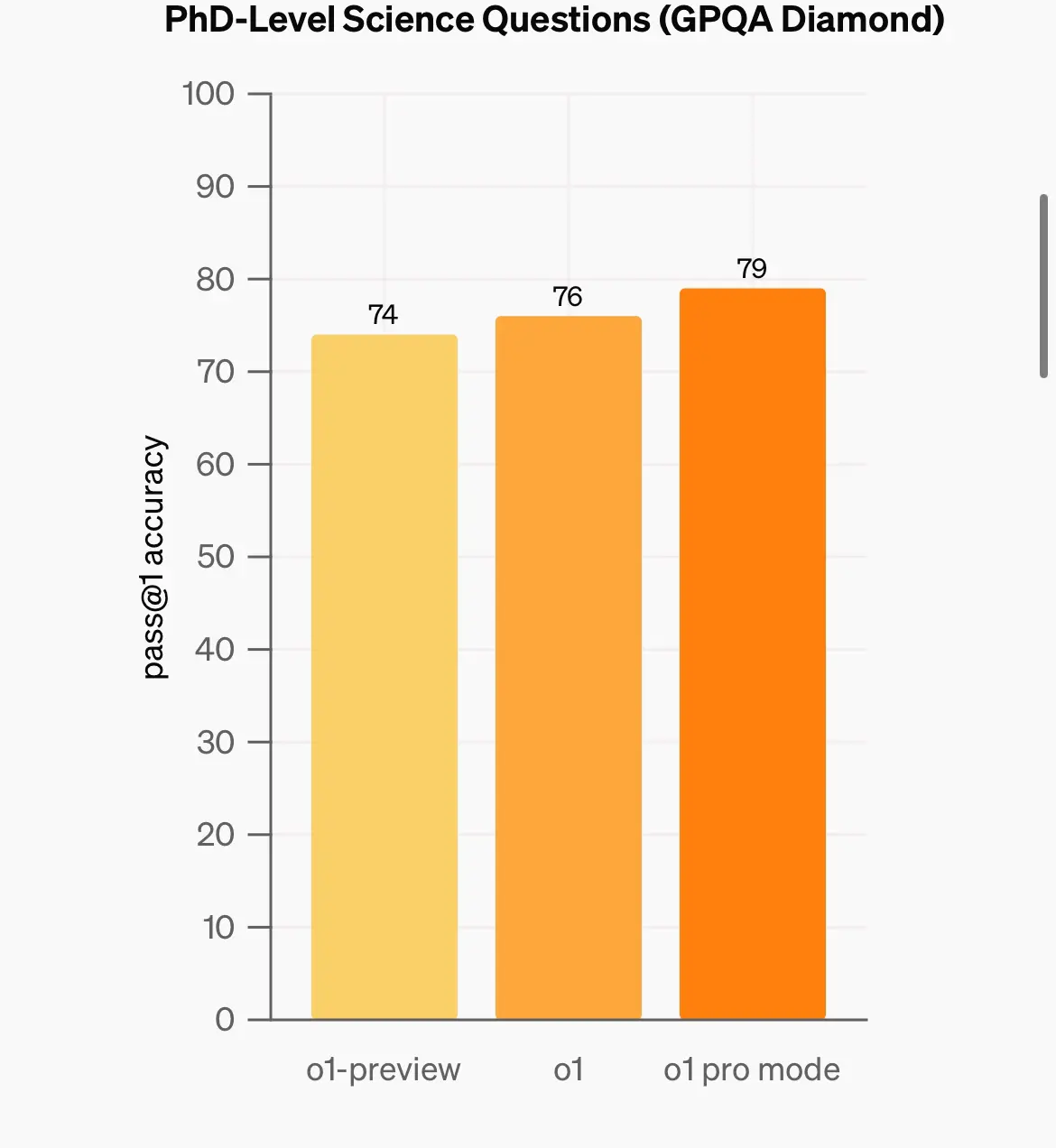
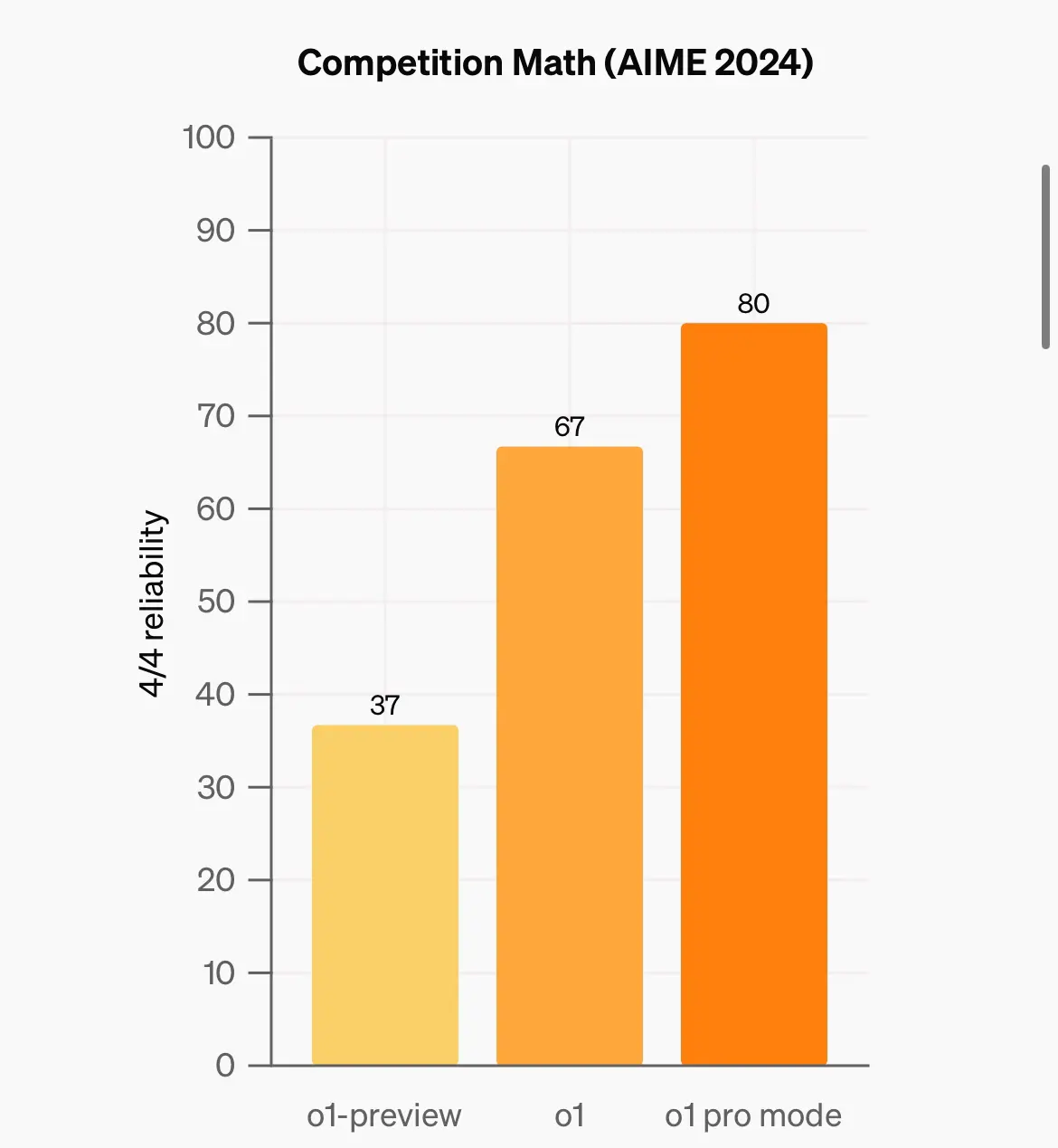
o1 pro 其實都有幾份benchmark 係open ai 自己公佈
包括係aime (數),competition coding , GPQA (phd science)
唔算好大進步
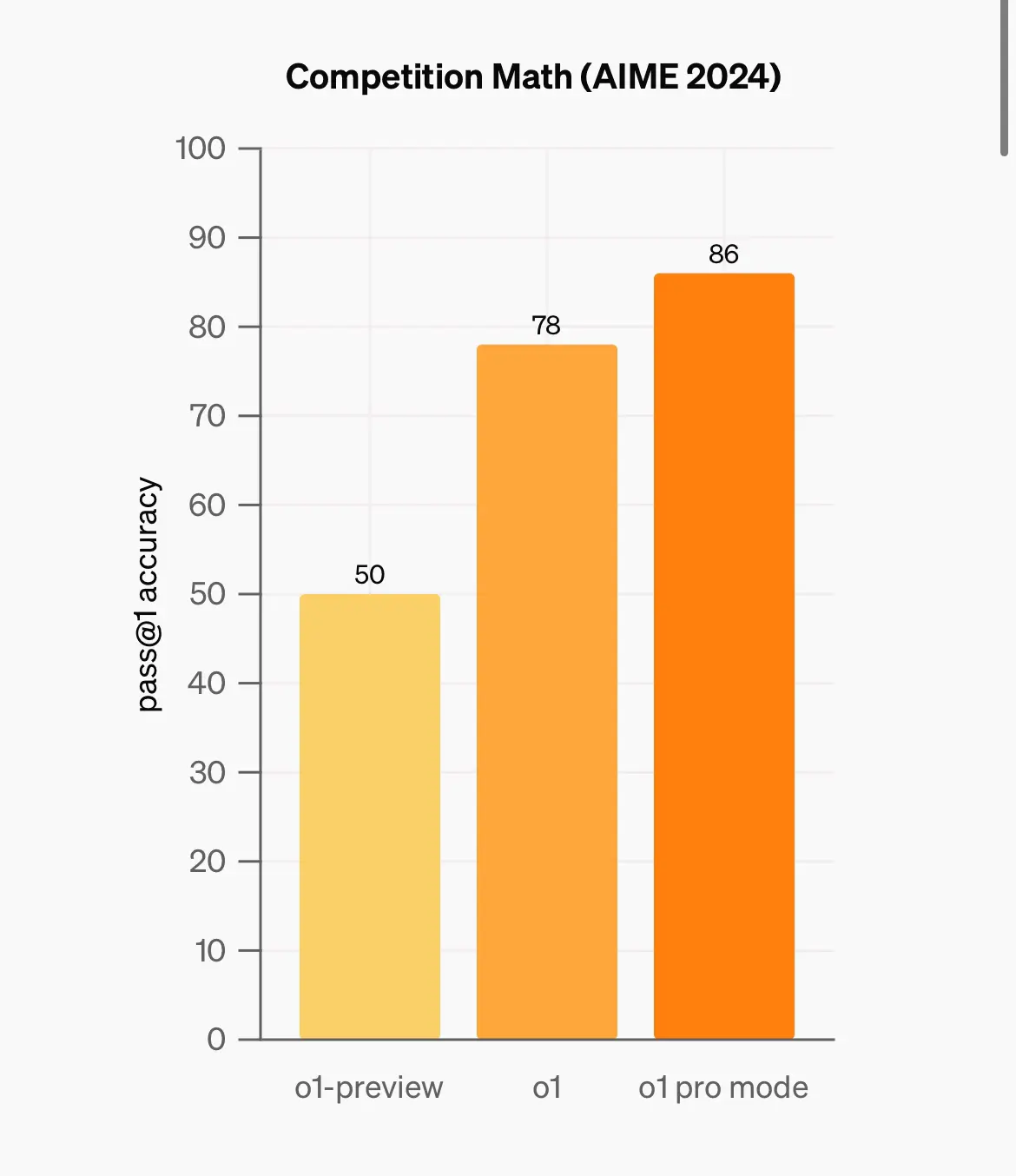
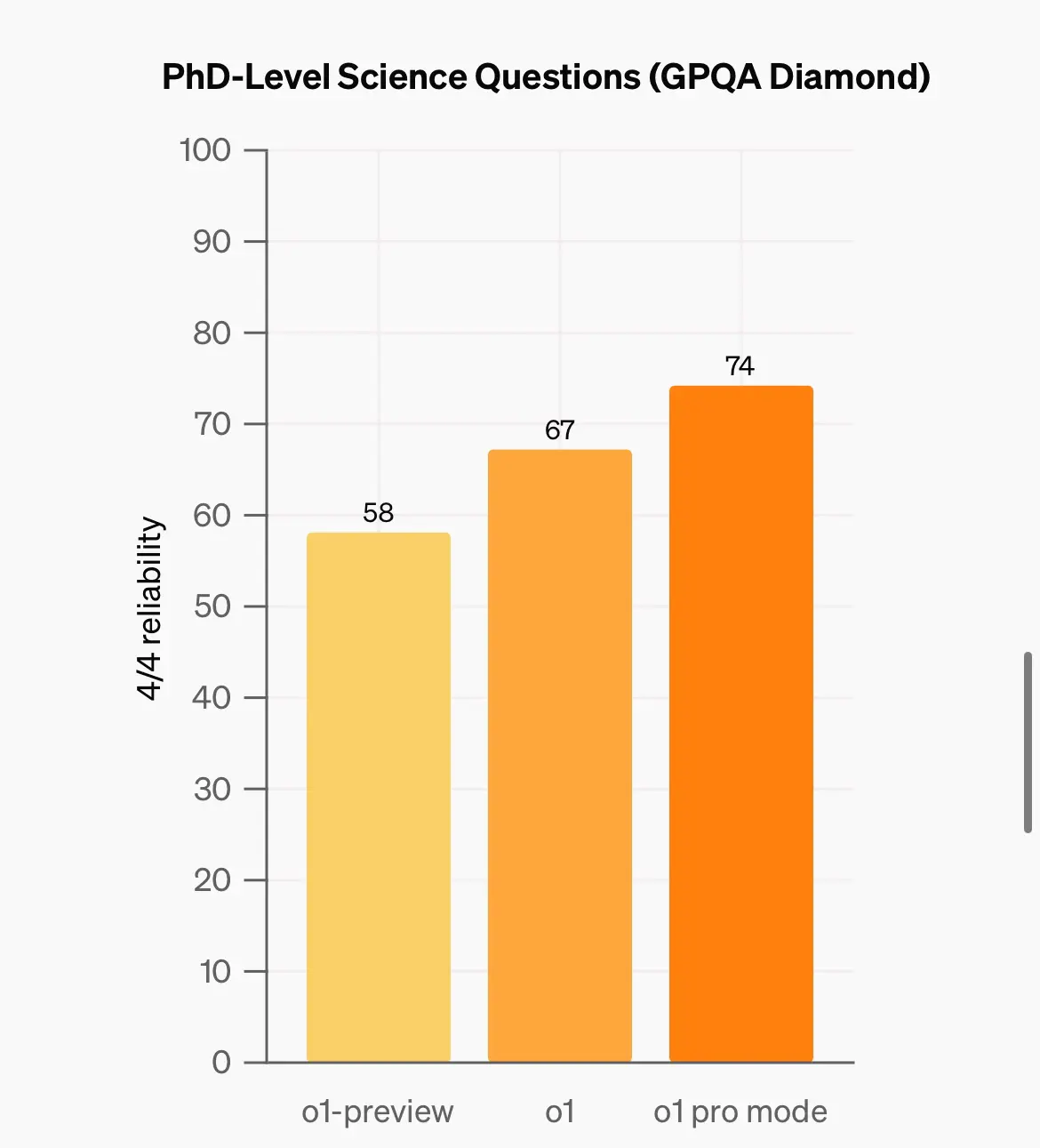
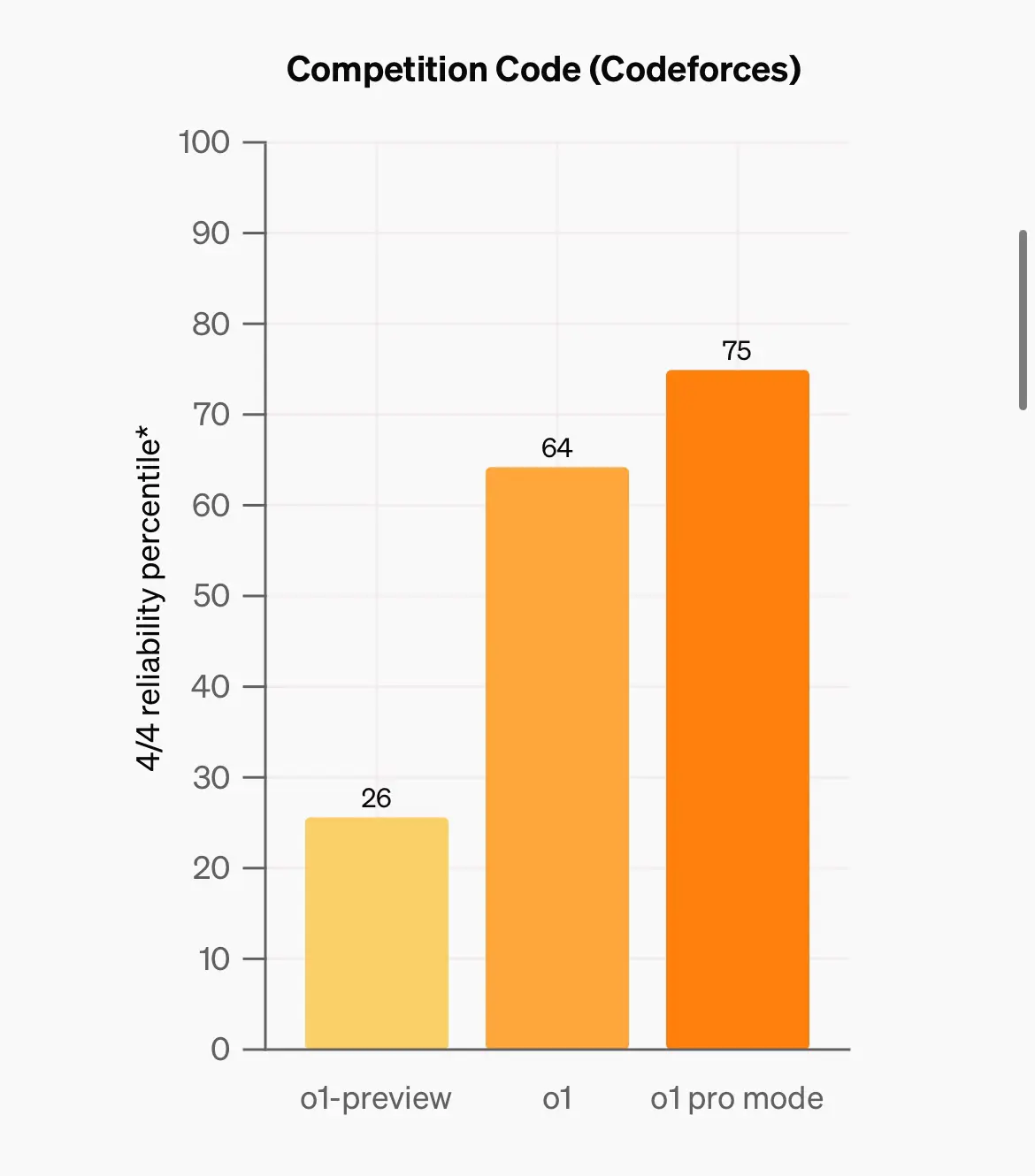
個差別比較大嘅係當model 係4/4 答啱嗰陣 先計答啱
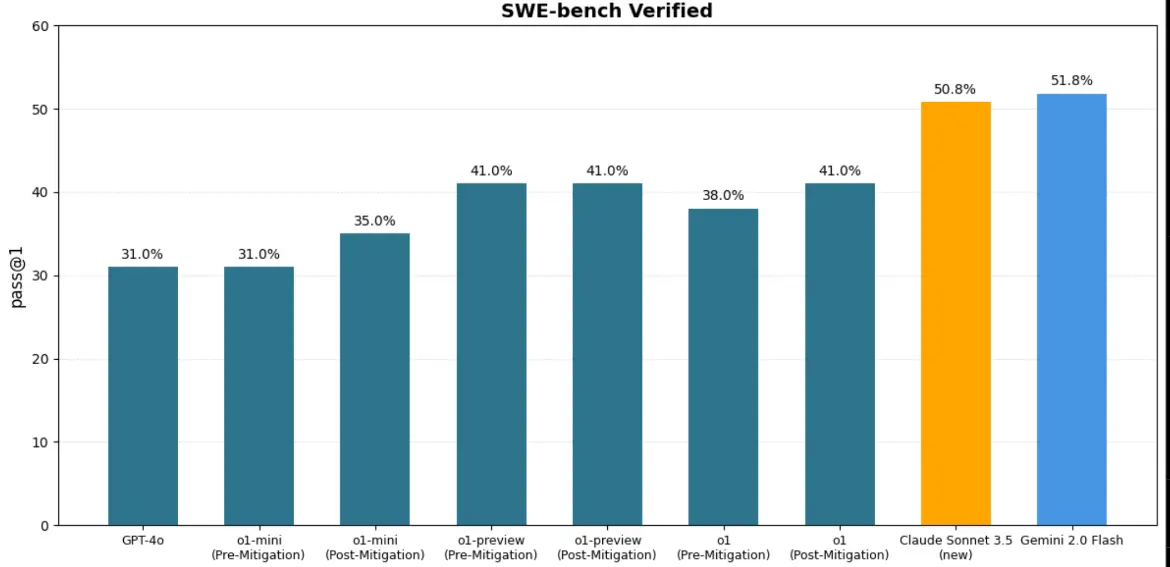
SWE Bench agentic coding benchmark (好似係) 比sonnet 表現差少少
有趣嘅係Flash 2.0 作為一個應該<100b 嘅細model SWE Bench 會係#1
Livecodebench 我唔識睇