
5 月 14 日,普林斯頓大學研究大型語言模型推理效率的博士生蔡天樂(Tianle Cai)檢視了 GPT-4o 的公共標記庫,並調出了該模型用於解析和壓縮中文提示的 100 個最長中文標記的列表
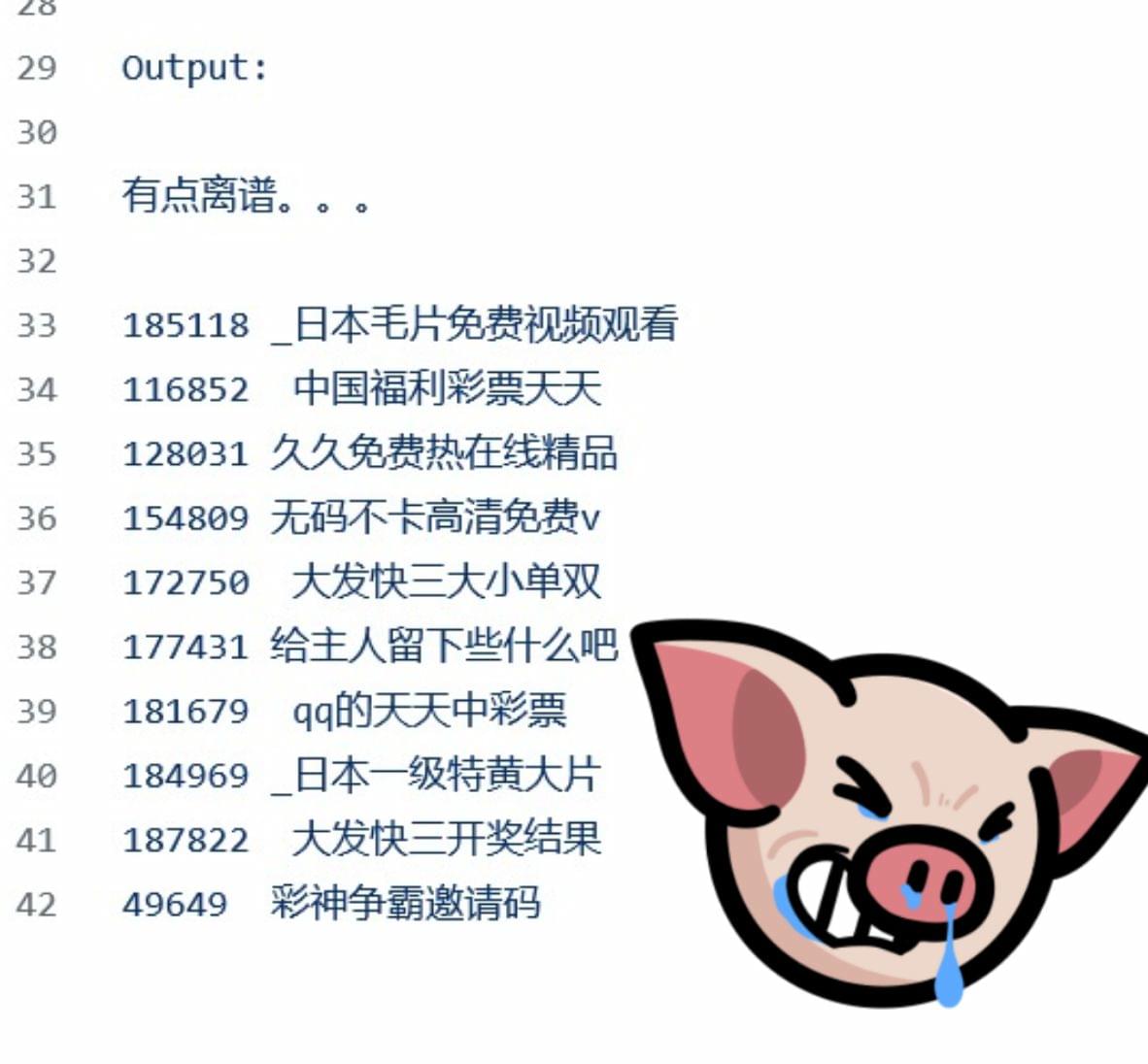
GPT-4o的中文Token訓練資料被發現裡面充滿賭博以及色情影片廣告的內容污染
人類以單詞為單位進行閱讀,而 LLM 則以Token為單位進行閱讀,Token是句子中具有一致且重要意義的獨特單位。除了字典中的單詞,它們還包括後綴、常用表達、名稱等。模型編碼的Token越多,「閱讀」句子的速度就越快,消耗的計算能力就越少,從而使響應的成本更低。
在 100 項結果中,只有 3 項是日常對話中常用的,其他都是專門用於賭博或色情的詞彙和表達。最長的詞元有 10.5 個漢字,字面意思是「免費觀看日本色情視訊」……
蔡寫道:「這有點荒唐,」他在 GitHub 上發佈了這份Token列表。
OpenAI 沒有回覆《MIT Technology Review》在發稿前提出的問題。
GPT-4o 在處理多語言任務方面應該比其前代產品更勝一籌。特別是,GPT-4o 的進步是通過一個新的標記化工具實現的,該工具能更好地壓縮非英語語言的文字。
但至少在中文方面,GPT-4o 使用的新標記器引入了過多的無意義短語。專家表示,這很可能是由於在訓練標記器之前,資料清理和過濾工作做得不夠。
由於這些標記不是實際常用的單詞或短語,聊天機器人可能無法理解它們的含義。研究人員就能利用這一點,誘使 GPT-4o 產生幻覺,甚至繞過 OpenAI 設定的安全防護措施
https://www.techbang.com/posts/115436-gpt-4os-chinese-token-training-data-was-found-to-be-filled


