
Leveraged ETF 討論區 (56)
Outliers
1001 回覆
2 Like
2 Dislike
第 1 頁第 2 頁第 3 頁第 4 頁第 5 頁第 6 頁第 7 頁第 8 頁第 9 頁第 10 頁第 11 頁第 12 頁第 13 頁第 14 頁第 15 頁第 16 頁第 17 頁第 18 頁第 19 頁第 20 頁第 21 頁第 22 頁第 23 頁第 24 頁第 25 頁第 26 頁第 27 頁第 28 頁第 29 頁第 30 頁第 31 頁第 32 頁第 33 頁第 34 頁第 35 頁第 36 頁第 37 頁第 38 頁第 39 頁第 40 頁第 41 頁
公司電腦點開VPN
戶口夠唔夠錢
有冇揀埋複雜槓桿產品
有冇揀埋複雜槓桿產品

將要做嘅嘢send去自己手機,再用自己手機問ChatGPT
補充多少少
CPI量度嘅係消費者支付嘅價格,但係一般消費者唔會直接買原油
所以原油價格上升同消費者支付嘅價格上升之間又會有延遲
現實世界複雜過textbook好多
CPI量度嘅係消費者支付嘅價格,但係一般消費者唔會直接買原油
所以原油價格上升同消費者支付嘅價格上升之間又會有延遲
現實世界複雜過textbook好多
我已經用緊chatgpt幫自己寫好d code




件事太複雜唔係話睇多啲新聞就可以估得準
分享吓我觀察到嘅嘢都得嘅,但係不確定性好高,唔好當預言咁睇
同埋通脹數據係一回事,市場點解讀又係另一回事
- investing.com嘅預期係Core CPI 5.5% (MoM 0.4%) CPI 6.2% (0.5%),通脹下降幅度比之前兩個月慢
- Inflation Nowcasting估5.58%同6.44%,不過佢嘅模型淨係睇gasoline價格,幾乎肯定係高估咗
- 非農就業數據(調整後)比預期高好多
- 澳洲、西班牙通脹都超出預期
- 原油、汽油、白銀、銅價上升
咁樣睇嚟通脹會下跌,但跌幅細過之前三個月,為聯儲局加息提供更多理據
- 但係鮑威爾琴日先神情輕鬆好有自信咁講”disinflationary process in the U.S. economy has begun”,睇你對佢有幾大信心啦
- CPI改計法改咗兩樣嘢(https://lih.kg/yxedePX),第1項改動正正係影響居高不下且佔24%嘅OER,依項改動可以令2013-2016年嘅CPI下跌0.1%。2022-23年咁特殊,下跌幾多真係要搵幾個PhD嚟計。第2項改動投資Talk君1月29日條片話反而會令通脹上升,不過準確度我覺得未必高
- 投資Talk君今日條片都有分析通脹,佢有一句係話「核心通脹過去幾個月都有下降趨勢,最合理嘅假設係假設佢繼續跌」依句都有一定道理,睇你同唔同意啦
分享吓我觀察到嘅嘢都得嘅,但係不確定性好高,唔好當預言咁睇
同埋通脹數據係一回事,市場點解讀又係另一回事
- investing.com嘅預期係Core CPI 5.5% (MoM 0.4%) CPI 6.2% (0.5%),通脹下降幅度比之前兩個月慢
- Inflation Nowcasting估5.58%同6.44%,不過佢嘅模型淨係睇gasoline價格,幾乎肯定係高估咗
- 非農就業數據(調整後)比預期高好多
- 澳洲、西班牙通脹都超出預期
- 原油、汽油、白銀、銅價上升
咁樣睇嚟通脹會下跌,但跌幅細過之前三個月,為聯儲局加息提供更多理據
- 但係鮑威爾琴日先神情輕鬆好有自信咁講”disinflationary process in the U.S. economy has begun”,睇你對佢有幾大信心啦
- CPI改計法改咗兩樣嘢(https://lih.kg/yxedePX),第1項改動正正係影響居高不下且佔24%嘅OER,依項改動可以令2013-2016年嘅CPI下跌0.1%。2022-23年咁特殊,下跌幾多真係要搵幾個PhD嚟計。第2項改動投資Talk君1月29日條片話反而會令通脹上升,不過準確度我覺得未必高
- 投資Talk君今日條片都有分析通脹,佢有一句係話「核心通脹過去幾個月都有下降趨勢,最合理嘅假設係假設佢繼續跌」依句都有一定道理,睇你同唔同意啦
仲有M2 都幾十年黎再下跌
cls
依個係支持衰退嘅好強原因
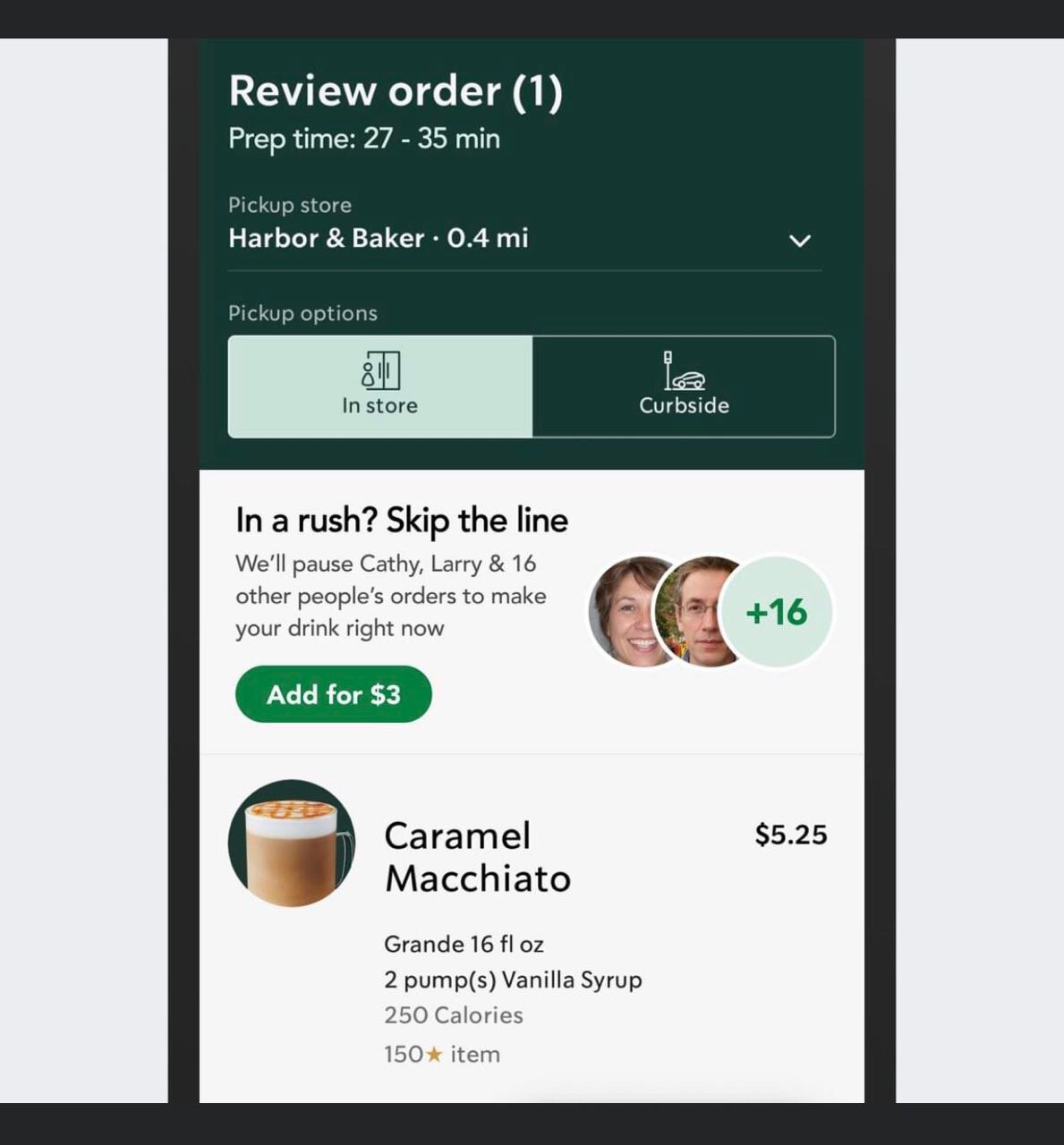
外國有人建議Starbucks出付費打尖服務

Google介紹新推出嘅AI,點知個AI答錯問題,股價盤前即刻大跌 


玩緊Quora個apps,速度快過網頁版ChatGPT好多 (https://apps.apple.com/hk/app/poe-fast-helpful-ai-chat/id1640745955)
問完佢之後,佢會建議你問其他follow up questions
例如我問佢去巴黎旅行有咩景點,佢會建議我問埋「巴黎鐵塔的開放時間是甚麼?」「請介紹一下羅浮宮的歷史背景。」
Suggested follow up questions依樣嘢有潛力放廣告,可以引導用家去問住宿、餐廳等等
陰謀論去諗,suggested follow up questions依樣嘢仲可以引導用家嘅思考方向。
可以引導你去諗某樣嘢 或者 引導你唔去諗某樣嘢
問完佢之後,佢會建議你問其他follow up questions
例如我問佢去巴黎旅行有咩景點,佢會建議我問埋「巴黎鐵塔的開放時間是甚麼?」「請介紹一下羅浮宮的歷史背景。」
Suggested follow up questions依樣嘢有潛力放廣告,可以引導用家去問住宿、餐廳等等
陰謀論去諗,suggested follow up questions依樣嘢仲可以引導用家嘅思考方向。
可以引導你去諗某樣嘢 或者 引導你唔去諗某樣嘢
啱啱問左GPT
入question limit 係2048 tokens
仲叫佢寫個python script to count token
入question limit 係2048 tokens
In the context of NLP (Natural Language Processing), a token is a sequence of characters that represents a single semantic unit in the text. Tokens are typically created by splitting the text into individual words or subwords, which are then used as the basic units of processing. For example, in the sentence "I like to play soccer," the individual words "I," "like," "to," "play," and "soccer" would each be considered a separate token.
仲叫佢寫個python script to count token
def count_tokens(text):
tokens = text.split()
return len(tokens)
text = "This is an example sentence."
print("Number of tokens:", count_tokens(text))